스레드 걱정 없는 파일 저장소 만들기
안드로이드에서 기기의 저장소에 파일을 저장하는 방법은 일반적인 자바의 파일 저장과 완전히 동일합니다. 예를 들어서 ‘Hello, World!‘라는 문자열을 파일로 저장하기 위해서는 다음과 같은 일반적인 코드를 사용하면 됩니다.
public void saveText(String text) {
try {
File file = new File(getFilesDir(), "test.txt");
FileWriter fw = new FileWriter(file);
fw.write(text);
fw.close();
} catch (IOException ie) {
ie.printStackTrace();
}
}
안드로이드 기기에서 앱이 사용하는 내부저장소(Internal Storage)의 루트 디렉토리를 가져오는 API인 getFilesDir() 메소드를 사용한 것 외에는 지극히 평범한 자바의 File I/O 코드입니다. 안드로이드는 편의를 위해서 파일의 Input Stream / Output Stream을 바로 가져올 수 있도록 해주는 openFileInput(), openFileOutput()등의 메소드, 혹은 위와 같이 파일을 저장할 루트를 가져오는 getFilesDir(), getCacheDir(), getExternalFilesDir() 등과 같은 메소드를 제외하고는 특별히 파일 입출력과 관련된 API를 제공해주지는 않고 있습니다. 그냥 일반적인 자바의 파일 입출력 API를 그대로 사용해도 아무 문제가 없고 실제로 대부분 그렇게 사용합니다. 실제로 앱이 사용되는 것을 고려하여서 화면에 있는 버튼을 누르면 무엇인가를 파일로 저장하도록 코드를 작성해보겠습니다. 이 역시 특별한 API를 사용하지는 않고 화면의 버튼을 가져오는 findViewById 메소드와 버튼이 눌렸을 때의 이벤트를 처리하는 setOnClickListener 메소드를 사용하면 됩니다.
Button saveButton = (Button) findViewById(R.id.saveButton);
saveButton.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
saveText("Hello, World! " + System.currentTimeMillis());
}
});
별로 특별할 것은 없습니다. saveButton이라는 ID를 가진 버튼을 누르면 위에서 작성한 saveText 메소드에 특정 메시지와 현재 타임스탬프를 저장하는 매우 기초적인 코드입니다. 위 saveText 메소드도 아무 문제가 없고 아래 saveButton에 대한 코드도 아무 문제가 없으므로 이 코드들은 아무 문제가 없어야 합니다. 그리고 실제로 코드를 작성해서 앱을 실행하고 돌려봐도 아무 문제가 발생하지 않습니다. 위 코드를 조금 응용해서 파일을 읽어서 화면에 표시해주는 메소드를 만들어서 검증을 해봐도 여전히 앱은 잘 동작합니다. 실제로 안드로이드 프로그래밍의 쉬운 접근성은 이렇게 기본적인 코드들이 자바 API를 그대로 사용하거나 기존 자바 프로그래밍에서 해오던 것들과 크게 다르지 않은 같은 스타일의 API를 사용하기 때문이기도 하고, 이러한 요소들이 보통의 자바 프로그래머들이 안드로이드 개발자로 전환하는 비용을 매우 낮춰주는 것도 사실입니다. 하지만 사실은 위 코드는 문제가 조금 있습니다. 위에서 보여드린 매우 쉬운 코드들과는 반대로 이번에는 어려울 수도 있는 코드를 보여드리겠습니다.
StrictMode.setThreadPolicy(
new StrictMode.ThreadPolicy.Builder()
.detectDiskWrites()
.penaltyDeath()
.build());
이 코드를 앱의 적당한 시작 지점, 보통 Activity의 onCreate() 라이프사이클 메소드 정도에 추가한 뒤 앱을 실행합니다. 그리고 마찬가지로 앱에 등장한 Save 버튼을 눌러서 파일 저장을 시도합니다. 위에서 매우 문제 없이 작동했던 동작이기 때문에 별 문제가 없어야 되지만 실제로 앱을 실행해서 파일 저장을 시도하면 앱이 종료됩니다. 이 때 로그를 보면 다음과 같은 로그를 확인할 수 있습니다.
FATAL EXCEPTION: main
Process: io.bga.writesome, PID: 27543
android.os.StrictMode$StrictModeViolation: policy=262145 violation=1
at android.os.StrictMode.executeDeathPenalty(StrictMode.java:1505)
at android.os.StrictMode.-wrap3(StrictMode.java)
at android.os.StrictMode$AndroidBlockGuardPolicy.handleViolation(StrictMode.java:1498)
at android.os.StrictMode$AndroidBlockGuardPolicy.handleViolationWithTimingAttempt(StrictMode.java:1325)
at android.os.StrictMode$AndroidBlockGuardPolicy.startHandlingViolationException(StrictMode.java:1295)
at android.os.StrictMode$AndroidBlockGuardPolicy.onWriteToDisk(StrictMode.java:1224)
at libcore.io.BlockGuardOs.write(BlockGuardOs.java:312)
at libcore.io.IoBridge.write(IoBridge.java:493)
at java.io.FileOutputStream.write(FileOutputStream.java:186)
at java.io.OutputStreamWriter.flushBytes(OutputStreamWriter.java:170)
at java.io.OutputStreamWriter.close(OutputStreamWriter.java:143)
at io.bga.writesome.MainActivity.saveText(MainActivity.java:64)
at io.bga.writesome.MainActivity$1.onClick(MainActivity.java:35)
로그를 자세히 보면 앱에서 버튼을 눌러서 onClick 메소드가 호출되고, onClick 메소드는 저희가 작성한 코드를 따라서 saveText 메소드를 호출했습니다. saveText 메소드는 일반적인 자바의 파일 출력 동작을 수행했으나, 실제로 파일을 저장하는 순간 BlockGuardOs 라는 클래스가 개입을 하더니 StrictMode 클래스가 executeDeathPenalty 메소드를 실행해서 앱을 종료시켜버렸습니다. 저희가 위에서 StrictMode.setThreadPolicy 메소드를 추가하자마자 이런 일이 발생했으므로 이 오류는 저 메소드와 관련이 있으리라 쉽게 추측이 가능합니다. 그리고 실제로 메소드 내에서 detectDiskWrite, penaltyDeath등의 수상한 빌더 메소드들을 같이 호출해서 무엇인가를 설정해줬으므로 파일을 작성하다가 앱이 죽어버린 것은 위 StrictMode 설정에서 기인했다는 점은 매우 명백합니다. 물론 일반적인 버그 픽스의 흐름에 따라서 추가했던 구문을 다시 지워주면 앱은 다시 완벽하게 동작합니다.
하지만 ‘완벽하게 동작한다’라는 말에는 조금 어폐가 있습니다. 완벽한 파일 출력 코드와 완벽한 이벤트 핸들링 코드가 결합되면 그 코드는 적어도 안드로이드 시스템에서는 절대 완벽하지 않습니다. 그 코드는 잠재적으로 매우 큰 문제점을 가지고 있습니다. StrictMode.setThreadPolicy 메소드는 이러한 잠재적인 문제점이 발생하는지 감시하고 있다가 문제점이 발생하는 순간 개발자에게 안내를 해주는 메소드입니다. (다만, 그 안내의 결과로 앱이 죽어버리는 것이 다소 극단적이라면 penaltyLog(앱은 그대로 살려두고 로그만 남김) 혹은 penaltyDialog(앱은 살려주고 다이얼로그만 띄움) 등의 메소드로 대체할 수는 있습니다.)
위 코드가 가지고 있는 잠재적인 문제점은 사실 코드 자체의 단순함에 비하면 조금 복잡합니다. 이를 이해하기 위해서는 안드로이드의 스레드 관리에 대한 대강의 지식이 필요합니다. 기본적으로 시장에 출시된 안드로이드 기기들은 듀얼코어 이상의 CPU를 가지고 있으며, 저희가 많이 사용하는 하이엔드 급의 안드로이드 기기들은 적어도 4개에서 많으면 8개 까지의 코어를 가지고 있습니다. 이는 저희 회사에 지급되는 OA 장비의 코어 숫자(2개 혹은 4개)와 비교해서도 일반적으로 더 많은 코어의 숫자로 전력관리 등의 이유로 클럭은 다소 낮지만 자잘한 작업을 동시에 수행하는 능력은 꽤 강력하다고 볼 수 있습니다. 이러한 멀티 코어 아키텍처를 굳이 활용하지 않을 이유도 없기 때문에 안드로이드 OS는 기본적으로 UI, 그러니까 사용자의 입력을 처리하고 화면에 뭔가를 표시하는 동작을 하는 스레드를 만들어서 유지하면서 동시에 개발자들이 몇 개의 스레드를 원하는 만큼 추가로 더 만들어서 사용할 수 있도록 지원해주고 있습니다. 안드로이드 OS에서 화면 입출력 처리를 위해 사용하는 스레드를 UI스레드 라고 부르며, 일반적인 안드로이드 개발에서는 UI스레드가 가장 기본적인 스레드가 되기 때문에 UI스레드는 흔히 메인스레드(Main Thread)라는 이름으로도 불립니다. 그리고 UI스레드를 제외한 다른 모든 스레드를 백그라운드 스레드(Background Thread) 혹은 워커 스레드(Worker Thread)라고 부르며 역시 두 개의 이름이 모두 일반적으로 사용됩니다.
개발자는 자신이 작성한 코드가 UI스레드에서 동작하는지 혹은 워커 스레드에서 동작하는지를 구분하기 위해서 다음과 같은 Support 라이브러리의 어노테이션을 사용할 수 있습니다.
@UiThread
public void printMessage(String message) {
}
@WorkerThread
public void calculateMoney(int id) {
}
주의하실 점은, 어노테이션을 붙인다고 해서 그 메소드가 알아서 백그라운드에서 돌거나 UI 스레드에서 돌아가지는 않는다는 점입니다. 그렇다면 어떻게 개발자가 특정 코드를 UI 스레드에서 동작하도록 혹은 워커 스레드에서 동작하도록 유도할 수 있을까요? 만약 특정한 동작 (보통 시간이 오래 걸리는 계산 작업)을 워커 스레드에서 돌리고 싶다면 위의 파일 입출력의 예와 마찬가지로 그냥 해당 코드를 자바의 스레드 API를 사용해서 별도로 분리하면 됩니다.
Thread thread = new Thread(new Runnable() {
@Override @WorkerThread
public void run() {
// 뭔가 오래 걸리는 작업을 수행한다
}
});
thread.start();
다만, 파일 입출력과 다르게 스레드의 사용은 일반적으로 스레드 API를 직접 사용하기 보다는 안드로이드에서 제공하는 다른 형태의 API나 메소드들을 많이 사용합니다. (물론 Thread API를 사용해야 유리한 경우도 여전히 존재합니다.) 다만 해당 주제는 여기에서 이야기 하고자 하는 주제와는 조금 다르기 때문에 굳이 언급하지는 않겠습니다.
그렇다면 워커 스레드가 아닌 UI 스레드에서 코드를 동작하게 하고 싶다면 어떻게 해야 될까요? 방법은 매우 단순합니다. UI 스레드에서 호출하는 모든 메소드들은 위 코드처럼 별도의 Thread로 명시적으로 분리하지 않는 이상 모두 UI 스레드 위에서 실행됩니다. 조금 더 단순하게 생각하면 일반적인 안드로이드 개발에서 사용하는 모든 코드들이 다 UI 스레드에서 동작한다고 보셔도 크게 틀린 말은 아닙니다. 그리고 모든 문제는 여기에서 부터 시작됩니다.
saveButton.setOnClickListener(new View.OnClickListener() {
@Override @UiThread
public void onClick(View v) {
saveText("Hello, World! " + System.currentTimeMillis());
}
});
위에서 버튼에 이벤트를 연결하기 위해서 onClickListener를 설정했습니다. 그리고 보통 이러한 종류의 코드는 onCreate 혹은 onViewCreated 등의 라이프사이클 메소드 상에서 정의됩니다. 설령 다른 곳에서 정의했다고 해도 크게 다를 것은 없습니다. onClick 이벤트는 억지성이 짙은 코드를 작성하지 않는 이상에야 UI 스레드상에서 발생할 수 밖에 없고, (사용자의 ‘입력’을 받아서 실행되는 메소드니까요) 이 ‘UI 스레드에서 실행된’ onClick 메소드는 saveText 메소드를 호출합니다. 메소드가 호출되는 중간에 스레드가 바뀌는 일은 없으므로 saveText 메소드 역시 UI 스레드 위에서 돌아가게 됩니다. 그리고 위에서 작성했던 것 처럼 saveText 메소드는 파일 입출력 API를 사용하여 파일을 저장합니다. 물론 해당 동작도 UI 스레드 위에서 돌아가겠죠. 이해를 돕기 위해서 코드를 살짝 바꿔보겠습니다.
saveButton.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
SystemClock.sleep(10000);
}
});
이런 식으로 코드를 작성할 사람은 아무도 없겠지만, 저장 버튼이 눌렸을 때 10초간 대기하도록 했습니다. 물론 해당 대기는 UI 스레드 위에서 이루어집니다. 앱을 실행하고 버튼을 눌러보면 아무 일도 일어나지 않습니다. 정말 지나칠 정도로 아무일도 일어나지 않습니다. 무슨 말이냐면 버튼을 누른 순간 10초 동안은 화면에 무엇인가가 나타나지 않습니다. 다른 버튼들이 있다고 해도 그 버튼들을 누를 수도 없습니다. 왜냐하면 UI 스레드는 10초간 대기 상태에 들어갔고, 이 말은 다시 말해서 ‘10초동안은 화면 출력과 사용자 입력을 처리하지 않는다.‘라는 의미가 되기 때문입니다. 일반적인 설정이라면 5초 정도 지난 뒤에는 안드로이드 OS가 앱 동작이 심상치 않은 것을 판단하고 다음과 같은 다이얼로그를 출력해줄 것입니다. (안드로이드를 실제로 사용하시는 분이라면 가끔 보셨을지도 모릅니다.)
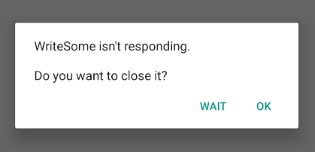
이 다이얼로그는 ANR (Application Not Responding) 이라고 불리며, 해당 다이얼로그가 발생한 사실을 앱 개발자에게 알려주면 높은 확률로 해당 개발자에게 수치심을 유발시킬 수 있습니다. 위 다이얼로그는 안드로이드 앱이 UI 스레드 상에서 특정 시간 이상 입출력을 수행하지 못하는 경우 발생합니다. 사실 사용자 입장에서도 뭔가를 눌렀는데 아무 표시도 되지 않고 입력도 받지 않고 앱이 멈춰있다면 기분이 좋을리가 없습니다. 20년 전쯤 쓰여진 책에서는 보통 사용자가 ‘뭔가 이상하다’ ‘너무 느리다’ ‘답답하다’라고 생각하는 시간을 0.5초 정도로 잡았었는데 요즘에는 사람들이 더 급해진 것인지 아니면 더 빠른 반응에 익숙해진 것인지, 각종 플랫폼의 개발 문서들에서 권장하는 반응속도(사용자가 입력을 하고 나서 그에 대한 피드백을 인지할 때 까지의 시간)의 제한이 0.1초 까지 줄어들었습니다. 즉, 개발자들은 가급적이면 onClick 메소드가 실행된 순간 이런저런 작업을 하더라도 최소한 0.1초 내에는 사용자에게 뭔가 결과를 보여주어야 합니다. 보여줄 자신이 없다면 기다리라는 표시(모래시계나 빙글빙글 돌아가는 표시나)라도 해주어야 합니다. 이러한 제약에 비하면 5초 동안이나 아무 동작을 하지 않았을때 발생하는 저 다이얼로그는 충분히 많이 기다려준 것이라고 할 수 있고 (옛날 기준으로도 10배, 요즘 기준으로는 50배나 더 인내심을 가지고 기다려준 것입니다) 충분히 개발자들이 보기 싫어할 만한 다이얼로그가 맞다고 할 수 있습니다.
가장 위에서 작성한, ‘버튼을 눌렀을 때 파일을 저장하는’ 코드의 문제는 여기에 있습니다. 파일 저장은 사실 순식간에 이루어집니다. 위 메소드의 경우 상황에 따라 다르겠지만 일반적으로 5~10ms 이상은 소요되지 않을 것입니다. 버튼을 누르는 순간 앱이 멈춰있는 시간이 0.01초 정도가 되는 것이니 사용자들은 앱이 멈췄다는 사실을 알지도 못할 것입니다. 그렇다면 굳이 penaltyDeath나 penaltyDialog 등의 설정을 줘서 사용자들이 눈치 채지도 못했는데 ‘사실 이 앱은 개발자가 실수해서 잠시 멈칫했었음’이라고 알려줄 필요가 있을까요? 보통은 없습니다. 그래서 보통 안드로이드 개발을 할 때는 그냥 UI 스레드에서 파일을 저장하거나 읽고, StrictMode 설정은 하지 않습니다. (하더라도 릴리즈 할 떄는 빼버립니다.)
그렇다면 ‘일반적인’ 케이스에서 파일 입출력은 별 문제가 없다면 왜 초반에 설명한 코드가 ‘문제가 있다’라고 하는 것이고 굳이 StrictMode를 설정해가면서 저렇게 작성한 코드가 없는지 찾아내고자 하는 것일까요? 일반적인 개발 감각을 가지고 계신 분이라면 잠재적인 문제점을 예측하기가 크게 어렵지는 않을 것 같습니다. 문제가 없어 보이는 코드를 문제가 발생하도록 만들어보겠습니다.
byte[] temp = new byte[1000 * 1000 * 10];
new Random().nextBytes(temp);
final String longString = new String(temp);
saveText(longString);
임의의 10메가 바이트 정도의 문자열을 생성하고 해당 문자열을 위 메소드를 이용해서 저장하도록 했습니다. 10메가 바이트 정도의 파일 입출력이 그렇게 흔한 것은 아니지만 그렇다고 발생하지 않을 것이라 장담하기도 어려울 것입니다. 제 개인적인 프로젝트 경험으로는 진도 5정도의 지진과 비슷한 빈도로 발생했었습니다. 저 코드를 실행하면 앱이 눈에 띄게 멈추는 것이 보입니다. 시간을 측정해서 로그를 찍어보니 다음과 같은 결과를 얻을 수 있었습니다.
D/Time: 4194ms
Choreographer: Skipped 252 frames! The application may be doing too much work on its main thread.
파일을 저장하는데 총 4.2초가 걸렸습니다. 이는 앱이 ANR의 문턱 (수치심의 문턱이라고 할 수도 있겠습니다.) 까지 갔었다는 뜻입니다. 저는 이 코드를 에뮬레이터에서 돌렸었는데 실제 기기에서 돌려보면 이 보다 더 빠를지 느릴지 잘 모르겠습니다. 하지만 확실한 것은 저사양의 디바이스에서 돌리거나 문자열의 길이가 20메가 바이트 정도만 됐어도 이 앱에서 ANR이 발생하지 않을 것이라고는 절대 장담할 수 없었을 것입니다. 애초에 그 전에 4초 동안이나 앱이 멈춰있었던 것도 문제입니다. 로그를 보면 안드로이드 OS는 252 프레임이 표시되지 않고 넘어갔다. 메인 스레드에서 너무 많은 일을 하고 있는 것 같다. 라고 경고를 하고 있는데, 그렇지 않아도 앱이 느리게 동작해서 심란한 상황에서 기계가 이런 지적을 하면 기분이 더 나빠질 수 밖에 없습니다. (물론 그 지적이 매우 정확히기 때문에 기분이 나쁜 것도 있습니다.) 안드로이드는 (iOS에 비해서 부드럽지 못하다는 세간의 인식과 달리) 1초에 60프레임의 그래픽 출력을 보여주는데 252 프레임을 60으로 나누어보면 실제로 4.2초간 화면이 표시되지 않고 넘어갔다는 사실을 알 수 있습니다.
이렇게 앱의 반응성과 자존감이 동시에 낮아질 때 개발자들은 어떻게 이 문제를 해결해야 될까요? 아쉽지만 퇴각검색(Back Tracking)이나 동적계획법(Dynamic Programming), 깊이 우선 탐색(DFS)이나 너비 우선 탐색(BFS) 등등의 알고리즘으로는 이 문제를 해결 할 수 없습니다. 시간이 오래 걸리는 작업이 입출력을 방해하지 않도록 하기 위해서는 해당 작업을 별도의 스레드에서 수행할 것이 요구됩니다. 거의 모든 안드로이드 디바이스는 2개 이상의 코어를 가지고 있으므로, 최소한 UI 스레드 외에 하나 이상의 작업은 동시에 수행할 수 있습니다. 만약 UI 스레드에서 모든 계산과 작업을 다 수행한다면 그 앱은 하나의 코어만 죽어라 일하게 만드는 앱이 될 것입니다. 물론 학교에서나 회사에서나 한 명만 죽어라 일하고 세 명이 일 없이 노는 경우가 발생하지 않는 것은 아니지만, 적어도 멀티 코어 환경에서 개발을 수행할 경우에는 가급적이면 할 수 있는 한은 여러 코어에 일감을 나눠주는 것이 하드웨어의 잠재력을 충분히 활용하는 좋은 코드가 될 수 있습니다. 물론 개발하는 앱이 돌아가는 디바이스가 몇 개의 코어를 가지고 있는지 특정하기도 쉽지 않고 (API를 사용하면 알 수는 있습니다.) 모든 작업을 일정하게 분배하는 것도 그렇게 쉬운 일은 아니므로 보통의 안드로이드 개발은 UI 스레드에서 수행할 일, 그리고 UI 스레드에서 수행하지 않을 일 두 가지를 분리해서 분배하는 것에 초점을 맞춥니다.
이 문제를 한 번 해결해 보겠습니다.
public void saveText(final String text) {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
long start = System.currentTimeMillis();
try {
File file = new File(getFilesDir(), "test.txt");
FileWriter fw = new FileWriter(file);
fw.write(text);
fw.close();
} catch (IOException ie) {
ie.printStackTrace();
}
Log.d("Background Time", (System.currentTimeMillis() - start) + "ms");
}
});
thread.start();
}
기존의 saveText 메소드를 Thread 클래스를 이용하여 별도 스레드에서 실행되도록 변경하였습니다. 이렇게 스레드를 날 것 그대로 쓰는 경우가 안드로이드에서 많지는 않지만 그렇다고 해서 큰 문제가 되거나 전혀 쓰이지 않는 것은 또 아닙니다. 이 코드를 실행해 보겠습니다.
D/UI Time: 0ms
D/Background Time: 4375ms
UI단의 onClick 메소드는 saveText 메소드를 호출합니다. saveText 메소드는 하나의 스레드 인스턴스를 생성하고 해당 스레드의 실행을 요청한 뒤 바로 메소드 수행을 종료합니다. onClick 메소드는 saveText 메소드의 호출 및 반환이 종료되었기 때문에 마찬가지로 그 자신의 실행을 종료합니다. 위 로그에서 확인할 수 있듯이, UI 스레드에서 수행한 작업은 스레드를 하나 생성하고 실행을 요청한 것이 전부이므로 수행 시각은 1ms 미만 정도만 소요됩니다. 안드로이드에서 1개의 프레임이 16ms를 차지하므로 (1000 / 60) 1ms 미만의 수행시각은 입력과 출력을 전혀 방해하지 않습니다. 실제로 파일 저장 버튼을 누른 직후 다른 UI 동작 (스크롤을 하거나 다른 버튼을 누르거나)을 해도 전혀 끊김이 없습니다.
반면에 파일을 저장하는 작업은 백그라운드에서 별도의 스레드로 진행됩니다. 파일을 저장하는 로직 자체는 변동이 없으므로 여전히 많은 양의 문자열을 저장할 때는 4초 이상의 시간이 필요합니다. 실제로 로그를 확인해보면 여전히 파일 저장에 4.3초 이상의 시간이 사용된 것을 볼 수 있습니다. 물론 UI를 처리하는 기기와 파일을 저장하는 기기가 같은 기기 이므로 파일을 저장하는 작업이 UI 작업의 수행에 전혀 영향을 주지 않는다고 단언하기는 조금 어렵겠지만, 일반적으로 여러 개의 코어를 활용할 수 있는 안드로이드 환경에서 이러한 백그라운드 작업은 지나치게 과도하지만 않으면 UI의 반응성에는 영향을 거의 주지 않습니다. 자원을 최대한 효율적으로 사용하는 것이 관리자와 개발자의 공통 목표 중 하나라고 본다면 적어도 이 코드는 개발자가 자기 몫을 다 했다고 이야기 할 수 있을 것입니다.
하지만 조금 경험이 있으신 자바 개발자라면 위 코드에도 의문을 제기할 수 있습니다. 예를 들어서 사용자가 저장 버튼을 연타한다면 어떻게 될까요? 스레드는 무제한으로 생성될 수 있는 것일까요? 대충 보면 스레드 내부에서 클래스 변수나 인스턴스 변수를 참조하거나 하는 일은 없어보입니다. 스레드가 사용하는 인스턴스들은 전부 스레드 내부에서 생성된 인스턴스 들이죠. 대충 보면 이 코드는 스레드 환경에 안전(Thread-Safe)한 코드로 보입니다. 하지만 조금 더 생각해보면 스레드 내부에서 사용되는 File 클래스의 인스턴스가 조금 수상해보입니다. File 클래스의 인스턴스는 항상 같은 파일인, test.txt 파일을 참조하도록 되어 있는데, 다수의 스레드가 동시에 동일한 자원에 접근할 수 있는 여지를 남겨두고 있습니다. 요즘 시대에 나오는 OS들이 설마 같은 자원에 동시에 접근한다고 데드락이 걸리거나 하는 일은 거의 없겠지만, 여러 개의 스레드 중 어떤 스레드가 먼저 실행되고 어떤 스레드가 나중에 실행될지 등에 대한 컨트롤이 쉽지 않기 때문에, 코드를 작성하는 시점 (Static Time)에 코드가 수행하는 시점(Runtime)의 동작을 완벽하게 예측할 수 없다는 위험을 가지고 있습니다. 보통 이런 불확실한 동작을 유도하는 코드들이 ‘잘 안되는데요?’ ‘내 자리에서는 잘 되는데?‘등의 논쟁을 유발시킵니다.
물론 문제를 해결하는 방법은 여러가지가 있습니다. synchronized 키워드를 써서 일종의 임계영역(Critical Section)을 만들 수도 있고, (그럼으로써 또 다른 문제를 야기할 수도 있고) wait, notify, sleep, yield 등의 스레드 API를 조금 더 적극적으로 활용해서 코드를 설계할 수도 있고, 독자적인 세마포어나 모니터를 설계해서 사용할 수도 있고, Concurrent 패키지에 쓸만한 클래스가 있나 확인해볼 수도, 안드로이드에서 제공하는 API들을 찾아볼 수도 있고, 아예 같은 파일이 생성되지 않도록 생각을 바꿔 볼 수도 있습니다.
이 시점에 한 번 따져봐야 될 것이 있습니다. 안드로이드를 개발하는 사람들이 이 모든 내용을 다 알고 있어야 하는가? 사실 그렇습니다. UI 스레드와 워커 스레드의 사용을 구분할 줄 모르고, 안다고 하더라도 스레드가 발생시킬 수 있는 다양한 문제점을 예측하고 해결할 수 없다면 그 개발자가 개발한 결과물이 ‘최선’이라고 믿을 수는 있어도 ‘최적’이라고 생각할 수는 없습니다. 이러한 내용을 모르고 개발하는 솔루션은 툭하면 느려지고 툭하면 튕기고 툭하면 잘못된 결과를 보여줄 것입니다. 하지만 개발의 기본기와 경험을 동시에 아우르는 이런 내용들을 모든 개발자들이 숙지한 상태에서 개발을 시작한다고 가정하는 것도 쉽지 않을 것 입니다.
위에서 언급한 내용들은 안드로이드 개발에 꽤 중요한 화두를 몇 가지 담고 있기는 하지만, 안드로이드 개발을 잘 하기 위해서는 저것 외에도 엄청나게 많은 사전지식이 필요합니다. 레이아웃은 어떻게 동작하는지, 각각의 클래스들의 라이프 사이클은 어떤지, 네트워크는 어떻게 동작하며 화면은 언제 갱신되는지, 스레드간의 메시지 전달은 어떻게 이루어지는지, 메모리 관리와 가비지 컬렉션(Garbage Collection)은 어떤 모델로 동작하는지, 오픈소스는 어떻게 포함시키고 어떻게 호출해야 되는지, 왜 코드 상의 메소드 숫자가 65535개를 넘으면 골치가 아파지는지 등등을 단시간 내, 그러니까 보통 회사에서 원하는 몇 시간, 혹은 몇 일, 길어도 1주일 정도 이내에 전부 알려주고 이해할 수 있도록 도와줄 수 있는 환상적인 해결책은 없습니다.
그렇다면 만약에 다음과 같이 문자열을 파일로 저장할 수 있다면 어떨까요?
storage.saveText("myText", text);
storage라는 인스턴스는 상위 클래스에서 이미 생성해서 상속해주었기 때문에 해당 클래스 내에서는 별도의 선언 없이 사용할 수 있다고 가정했습니다. 데이터를 저장하는 방식은 굉장히 여러가지 형태로 표현할 수 있지만, 단순한 문자열을 저장한다고 했을 때는 Key - Value 형태의 쌍으로 데이터를 저장하고 읽어오는 것이 가장 직관적입니다. 같은 맥락에서 파일로부터 문자열을 읽어오는 코드를 작성한다면 아마 다음과 같은 형태가 될 것 입니다.
String myText = storage.readText("myText");
이러한 방식은 충분히 단순하기 때문에 별다른 설명이 필요 없습니다. 만약 저 메소드들의 내부에서 파일 접근에 대한 자원 관리와 스레드 관리를 ‘알아서 잘’ 해준다면 많은 개발자들은 파일 하나 저장하기 위해서 복잡한 스레드 모델과 API를 외우지 않아도 충분히 효율적인 형태로 개발을 계속할 수 있습니다. 솔루션의 성격에 따라서 다르겠지만, 일반적인 비즈니스 로직을 모바일 화면으로 구현하는 형태의 프로젝트에서는 파일을 저장하는 코드는 보통 비즈니스 로직의 보조적인 형태로 사용되는 경우가 많기 때문에 개발자들이 파일 저장 자체에는 별다른 신경을 쓰지 않고 본연의 로직에 조금 더 집중할 수 있도록 해주는 효과도 기대할 수 있을 것입니다.
조금 더 확장해서 생각해보겠습니다. 파일을 저장했을 때 제대로 저장되었는지, 아니면 권한이나 남은 용량 등의 문제로 저장이 제대로 이루어지지 않았는지를 확인하고 싶다고 해보겠습니다. 이 경우 saveText 메소드가 저장 결과를 반환하도록 작성할 수 있습니다.
DataStoreResult result = storage.saveText("myText", text);
API의 단순성은 여전히 유지하고 있으며, 사용법도 여전히 어렵지 않습니다. 개발 경험이 조금만 있는 분이라면 DataStoreResult라는 클래스 내에 데이터 저장이 성공했는지 실패했는지 판단할 수 있는 메소드가 있을 것이라 쉽게 추측할 수 있을 것입니다. (그리고 아마 그 메소드의 이름은 isSuccess 정도가 될 것이라고 추측할 수도 있습니다.) 하지만 여기에서 한 가지 귀찮은 문제가 발생합니다. saveText 메소드를 잘 작성했다면, 안드로이드 플랫폼 내에서는 문자열을 저장하는 메소드가 저런 식으로 작성될 수는 없습니다. 왜냐하면 위에서 말했던 것 처럼 파일을 저장하는 동작은 별도의 스레드에서 이루어지는데, 별도의 스레드에서 이루어지는 작업은 그 결과를 비동기(Asynchronous)로 알려줄 수 있지, 저렇게 동기(Synchronous)화 된 반환값을 넘겨줄 수는 없습니다.
조금 어려운 방법이기는 하지만 Latch등을 이용하면 saveText 메소드를 수정해서 백그라운드 스레드에서 작업이 이루어지되, 결과를 동기화하여 반환하는 식으로 만드는 것도 아주 불가능 한 것은 아닙니다. 하지만 이 경우 saveText 메소드는 호출 하는 입장, 그러니까 UI 스레드 입장에서는 수행시간이 끔찍하게 오래 걸리는 메소드가 되어 버리기 때문에 굳이 그 고생을 해서 파일 저장을 별도의 스레드로 분리한 이유가 없어지게 됩니다. 때문에 파일을 저장하는 메소드는 적어도 UI 스레드에서는 다음과 같은 형태가 되어야 합니다.
storage.saveText("myText", text, new DataStoreCallback() {
@Override
public void onStoreComplete(DataStoreResult result) {
}
@Override
public void onStoreFail(DataStoreResult result) {
}
});
파일 저장을 요청하고 그 결과를 콜백 메소드(Callback Method)로 받을 수 있도록 시그니처를 변경하였습니다. result를 바로 반환 받는 것에 비해서 다소 복잡해졌지만, saveText 메소드가 반드시 비동기 호출로 동작해야 된다는 점을 감안하면 이 시그니처는 여전히 최선이라고 할 수 있습니다. 개발자들을 조금 더 배려해준다면, 결과에 대한 처리가 필요 없는 경우 콜백 전달 없이 메소드를 사용할 수 있도록 메소드를 오버로딩 (Overloading) 시켜줄 수 있을 것입니다.
개발자들이 안드로이드의 복잡한 이면을 알지 못하더라도 파일의 저장을 비교적 최선의 형태로 수행할 수 있도록 메소드를 만들어줬고, 그 결과에 대한 비동기 콜백까지 지원해주었습니다. 회사의 복잡한 요구사항을 수용하기 위해서 저장되는 파일이 매우 복잡하고 신뢰성 높은 로직에 의해서 암호화 되어야 한다고 해도, 해당 메소드의 내부가 바뀔 뿐 개발자들이 호출하는 방식은 크게 바뀔 일이 없을 것입니다. 사실 대부분 매우 기초적인 객체지향적 설계에 해당하기 때문에 그렇게 특별할 것은 없습니다. 하지만 이것으로 파일 저장과 관련된 모든 고려가 끝났을까요? 하나의 코드 조각을 더 보겠습니다.
@WorkerThread
public boolean doInBackground(Object... params) {
storage.saveText("myText", text, new DataStoreCallback() {
@Override
public void onStoreComplete(DataStoreResult result) {
}
@Override
public void onStoreFail(DataStoreResult result) {
}
});
}
위에서 작성했던 파일을 저장하는 코드가 그대로 사용되고 있습니다. 위에서 최적이라고 했으므로 이 코드 자체는 별 문제가 없어 보입니다. 하지만 문제는 이 코드가 실행되는 위치입니다. 안드로이드 개발을 할 때는 UI 스레드 위에서 동작을 정의하고 코드를 작성하는 일이 상당히 많기 때문에 위에서 했던 모든 설명은 UI 스레드에서 파일을 저장할 때의 문제점에 대해서 이야기를 했었습니다. 하지만 모든 파일 저장의 시작점이 UI 스레드가 되리라는 보장은 전혀 없습니다. 예를 들어서 네트워크 호출을 하고, 그 결과를 받아서 파일에 저장하는 코드를 작성해야 된다면 어떨까요? 안드로이드에서 네트워크 호출은 파일 저장 보다도 훨씬 더 강력하게 백그라운드 스레드에서의 실행이 강제되는 작업입니다. StrictMode를 설정하지 않더라도, UI 스레드에서 네트워크 호출을 수행하면 앱은 튕겨 나갑니다. 파일 저장이야 일반적인 경우에는 보통 짧은 시간 안에 수행되니까 UI 스레드에서 저장을 하더라도 눈감고 지나갈 수 있겠지만, 네트워크의 경우 상황에 따라서 5초 10초씩 응답이 지연되는 일이 굉장히 흔하기 때문에 UI 스레드에서의 호출 자체가 원천적으로 봉쇄되어 있는 것입니다.
그래서 보통 네트워크를 사용하는 API는 대부분 비동기로 사용하도록 작성되어 있고, 직접 HTTP 연결을 수행하는 경우에는 해당 연결 코드가 별도의 스레드에서 실행되도록 구성하여야 합니다. 만약에 네트워크 수행 및 파일을 저장한 전체 비즈니스 로직이 모두 별도 스레드에서 수행되도록 위 코드의 doInBackground 메소드에 작성되어 있다고 가정하겠습니다. doInBackground 메소드는 어노테이션을 보면 알 수 있듯이 백그라운드 스레드에서 동작하는 메소드입니다. 이 코드 내에서는 네트워크 호출도 동기로 이루어져야 합니다. 비동기 호출이 불가능한 것은 아니지만 적어도 콜백의 결과를 해당 메소드 내에서 핸들링 할 수는 없습니다. 같은 맥락에서 파일 저장 역시 동기화 된 호출이 이루어져야 합니다. 즉, 해당 메소드는 다음과 같은 형태를 가지는 것이 바람직 합니다.
@WorkerThread
public boolean doInBackground(Object... params) {
DataStoreResult result = storage.saveText("myText", text);
}
오히려 더 단순해졌습니다. 만약 해당 비동기 호출을 진행하는 클래스 자체에서도 UI 클래스들과 마찬가지로 별도의 공통 클래스를 가지고 storage 인스턴스를 알아서 생성해서 제공해준다면 개발자들은 UI 스레드에서의 화면 컨트롤 코드를 작성할 때와 백그라운드 스레드에서의 비즈니스 로직을 작성할 때 모두 신경이 분산되지 않는 선에서 파일 저장을 수행할 수 있을 것입니다. 결과적으로 같은 동작을 상속한 상위클래스에 따라서 동기화 된 호출만 가능하도록, 비동기화 된 호출만 가능하도록 나누어서 제공하는 것은 객체지향 적으로는 고민이 다소 필요한 도전이지만 자바에서는 인터페이스와 추상클래스를 적당히 활용하면 큰 어려움 없이 제공할 수 있습니다.
작년이 끝나갈 무렵, 저는 새로운 솔루션 개발 프로젝트를 준비하는 일을 진행한 적이 있었습니다. 당시 새로운 솔루션은 뭔가 모호한 계획 속에 있었지만 만들고자 하는 결과물이 비교적 도전적이라는 소리를 들었습니다. 본격적인 개발은 1월에 시작될 예정이었고, 안드로이드 개발 경험이 있는 개발자와 없는 개발자가 모두 투입될 수 있는 상황이었습니다. 위에서 말했던 것 처럼 안드로이드 개발에는 고려해야 될 내용이 너무 많았습니다. 로그 하나를 찍는 것 조차도 ‘Log 클래스 쓰세요’라고 단순하게 말하고 넘어갈 수 있는 상황이 아니었습니다. 파일 저장은 고려해야 될 내용 중에서는 비교적 명확하고 쉬운 문제에 해당했고, 보안과 관련된 문제, UI/UX와 관련된 문제, 성능과 효율성, 네트워크의 사용, 비즈니스 로직의 분리와 활용 등등 엔터프라이즈 레벨의 안드로이드 솔루션을 만드는 것은 생각보다 많은 부분의 준비가 필요한 일이었습니다. 최소한 그저 파일 하나 저장했을 뿐인데 상황에 따라 느려지거나 튕겨나가는 일은 없도록, 조금 더 나아가서는 안드로이드 개발에 경험이 있거나 없거나 자신이 알고 있는 것들을 이용해서 충분히 원하는 화면과 로직을 만들어 낼 수 있도록, 그러니까 개발자들이 쓸데없는 것에 신경쓰지 않고 충분히 자신의 역량을 발휘할 수 있도록 준비해주는 작업이 필요했던 것입니다. 이제 그 본격적인 준비과정을 이야기 해보겠습니다.
랜덤 데이터를 이용한 데모 환경 준비하기
저희가 기존에 진행했던 모바일 개발 프로젝트에서는 서버 인터페이스가 만들어지기 전에 화면을 먼저 만들어야 되는 일이 자주 있어서, 임시로 데이터를 보내주는 용도로 deployd를 많이 사용했었습니다. deployd는 자바스크립트 기반의 작은 서버로, 관리 페이지에 데이터를 입력하면 바로 Rest 형태로 데이터를 받아올 수 있도록 해주는 오픈소스 프로그램입니다.
클라이언트를 개발할 때 필요한 테스트 데이터들을 생성하기 위해서 저희는 초기에는 json-generator 라는 웹 페이지를 사용하였습니다. json-generator는 일정한 문법에 맞추어서 데이터 형태를 작성하면, 임의의 랜덤 데이터를 원하는 수량만큼 json 형태로 생성해주는 페이지였습니다. 예를 들어서 사람의 목록을 만들고 싶다면 다음과 같은 형태로 데이터 모델을 정의할 수 있습니다.
[
'{{repeat(100)}}',
{
name: '{{firstName()}} {{surname()}}',
age: '{{integer(10,50)}}',
gender: '{{gender()}}',
email: '{{email()}}',
phoneNumber: '010-{{integer(2000,9999)}}-{{integer(1000,9999)}}',
address: '{{integer(100, 999)}} {{street()}}, {{city()}}, {{state()}}, {{integer(100, 10000)}}'
}
]
이 모델을 json-ganerator에 올리면, 다음과 같은 형태로 임의의 사람 목록을 리턴해줍니다.
[
{
"name": "Sherry Waller",
"age": 27,
"gender": "female",
"email": "sherrywaller@circum.com",
"phoneNumber": "010-6175-6118",
"address": "266 Flatbush Avenue, Greenbush, Virginia, 8601"
},
{
"name": "Virgie Castillo",
"age": 41,
"gender": "female",
"email": "virgiecastillo@circum.com",
"phoneNumber": "010-7136-1532",
"address": "104 Navy Walk, Boomer, West Virginia, 9819"
},
{
"name": "Myra King",
"age": 27,
"gender": "female",
"email": "myraking@circum.com",
"phoneNumber": "010-6650-5710",
"address": "269 Eagle Street, Belfair, Alabama, 7452"
},
{
"name": "Rhodes Kaufman",
"age": 16,
"gender": "male",
"email": "rhodeskaufman@circum.com",
"phoneNumber": "010-5738-7424",
"address": "739 Lawn Court, Cornucopia, Oregon, 2025"
},
(후략)
저희는 이 json을 deployd에 업로드 해서 모바일 클라이언트에서 화면을 구성할 때 사용하였습니다. 물론 솔루션 개발이 진행되면 실제 서버 인터페이스와 연결하는 시점이 생기게 되고, 실제 테스트 DB에서 데이터를 받아와서 화면에 뿌려주기 시작하기 때문에 그 때 부터는 json-generator와 deployd의 활용도가 급격히 떨어지는 시점이 분명히 있었습니다. 다만 여기에서 약간의 아이디어를 얻은 것이 있었습니다. 만약에 솔루션이 적절한 랜덤 데이터를 스스로 생성할 수 있는 엔진을 내장할 수 있다면 뭔가 도움이 되지 않을까요?
솔루션이 스스로 임의의 데이터를 생성할 수 있다는 것은 크게 2가지 정도의 장점을 가집니다. 첫번째는 프로그램이 서버 없이 독립적으로 동작할 수 있다는 점입니다. 물론 서버 없이 돌아가기 때문에 정확한 데이터를 뿌려주거나 비즈니스 로직 처리가 분명하게 이루어지는 것은 아니겠지만, 이 솔루션이 어떤 화면들을 가지고 있고 어떤 기능을 가지고 있는지 정도를 소개할 때는 충분히 사용될 수 있을 것 같았습니다. 쉽게 말해서 영업 활동을 할 때 앱을 데모 모드로 돌릴 수 있는 것입니다. 그리고 다른 하나의 장점은, 솔루션이 얼마든지 많은 데이터를 생성할 수 있기 때문에 개발과 테스트에 개발자의 의도를 담을 수 있었다는 점입니다. 원한다면 목록을 100건이 아니라 1,000건이나 10,000건 혹은 무한대로 생성해서 부하가 걸리거나 메모리가 넘치지 않는지 확인해볼 수도 있고, 임의의 데이터를 의도적으로 ‘불완전하게’ 생성해주어서 특정한 경우에도 앱이 안정적으로 돌아가는지도 확인해 볼 수 있었습니다. 특정 케이스의 데이터가 없어서 개발이나 테스트가 자꾸 막히는 일도 줄일 수 있구요. 이러한 장점은 추후 UI 테스트를 자동화 할 때도 도움이 될 것이라고 생각했습니다.
사람들의 목록을 가져오는 코드를 자바로 작성한다면 다음과 같은 코드가 되면 편할 것 같았습니다.
List<Person> pserons = PersonDataGenerator.getInstance().generatePersonList();
하지만 실제로 Person 이라는 객체는 실제 개발을 진행할 때는 임의의 인터페이스 / 데이터 모델에 맞춘 특정 VO가 될 가능성이 높았고, 이러한 VO는 정말 무수히 많이 만들어질 가능성이 높았습니다. 때문에 모든 종류의 VO를 임의로 생성해주는 것은 현실적으로 불가능한 일에 가까웠습니다. 그래서 일단은 조금 더 낮은 레벨의 기초적인 데이터들을 만들어주는 API를 만들었습니다. 예를 들어서 임의의 숫자를 생성하는 API는 다음과 같은 형태가 될 수 있습니다.
int number = NumberCore.generateInteger();
하지만 실제로 생성되는 데이터가 의미를 가지려면 숫자를 생성하는 메소드가 조금 더 다양해져야 됩니다.
int generateInteger()
int generateInteger(final int max)
int generateInteger(final int min, final int max)
int generateInteger(final int min, final int max, final int step)
생성하고자 하는 테스트 데이터가 일정한 범위를 가질 수 있으므로 범위를 지정할 수 있도록 메소드를 몇 가지 추가했습니다. 물론 별로 어려울 것은 없는 일입니다. 만약 이러한 메소드를 제공해준다면, 임의의 사람을 생성하고자 할 때 다음과 같이 코드를 구성할 수 있을 것입니다.
Person person = new Person();
person.setAge(NumberCore.generateInteger(0,120));
이제 생성되는 사람은 0세에서 120세 사이의 범위에서 임의의 나이를 가지게 됩니다. 이렇게 1,000명 정도의 사람을 생성해서 화면에 뿌려준다면 아마 다양한 나이대의 사람들이 화면에 표시될 것입니다. 테스트 데이터로도 꽤 의미가 있을 것이구요. 예를 들어서 텍스트 뷰를 너무 좁게 만들어서 100세가 넘어가면 글자가 2줄이 되거나 잘리거나 하는 문제도 테스트 DB에 100세 이상의 데이터가 있느냐 없느냐와 관계 없이 미리 확인할 수 있을 것입니다. (물론 랜덤으로 생성되므로 가급적이면 충분히 많은 데이터를 생성해서 테스트 할 필요는 있습니다.)
하지만 여기서 한 가지 마음에 걸리는 것이 있습니다. 테스트 데이터가 단순히 개발단계에서의 테스트로 쓰인다면 이 정도로도 충분하겠지만, 영업 단계에서의 데모 데이터로 사용된다면 생성되는 데이터가 너무 무작위 성향을 가지는 것이 그렇게 좋지는 않을 것입니다. 예를 들어서 위 코드는 120세와 25세의 사람이 동일한 확률로 나타나게 됩니다. 물론 저희가 만드는 솔루션이 병원 시스템을 대상으로 하고 있기 때문에 일반적인 집단 보다는 저연령 혹은 고연령의 환자 비율이 높기는 하겠지만, 실제로 모든 나이대의 환자가 동일한 확률로 등장한다면 데이터가 상당히 어색해 보일 수 있습니다. 때문에 다음과 같은 메소드를 추가로 제공해줄 수 있습니다.
int generateIntegerWithNormalDistribution(final int min, final int max)
주어진 범위 내에서 정규분포를 이용하여 데이터를 생성합니다. 생성되는 데이터가 정말로 정규분포를 따른다면 중간값과 그 주변에 상당히 많은 숫자가 몰려 있을 것이고 중간값에서 멀어질 수록 적은 분포로 데이터가 나타나게 될 것 입니다. 이런 걸 어떻게 만들어 라고 생각하실 수도 있겠지만 자바의 Random 클래스에는 중간값이 0이고 표준편차가 1.0인 정규분포를 따르는 랜덤값을 생성해주는 nextGaussian() 메소드가 이미 존재하기 때문에 실제로는 매우 쉽게 구현할 수 있습니다. 저희가 일상생활에서 만나는 많은 데이터들이 실제로 정규분포를 따르기 때문에 이러한 종류의 데이터 생성은 꽤 의미가 있습니다. 같은 맥락에서 데이터의 집합을 생성하는 것도 어느 정도 고민이 필요한 부분이었습니다. 예를 들어서 저희는 주로 의료와 관련된 데이터를 다루기 때문에 그 사람의 심박수 라든지 체중, 혈압 등등의 생체 데이터를 그래프로 표시하거나 하는 일이 솔루션 마다 꼭 한 번 이상은 있었는데, (회사의 많은 분들이 그래프를 좋아하는 것 같았습니다.) 이러한 데이터는 정규분포 보다도 일정한 트랜드를 가지는 경우가 있습니다. 점점 증가하거나, 점점 감소하거나, 증가하더라도 일정하게 증가하거나, 지수적으로 증가하거나, 아니면 일정한 범위 내에서 왔다갔다 하거나. 특정한 트랜드를 가지고 있으면서도 가끔 튀는 값이 생기거나 하는 일들이 있을 수 있습니다. 예를 들어서 일정한 사이즈의 심박수 데이터를 그럴듯하게 생성하기 위해서는 다음과 같이 호출할 수 있습니다.
NumberCore.generateNumberCollection(size, 50, 100,
NumberCore.TRENDING_TRENDS, NumberCore.TrendingParameter.uneven(0.2))
위 코드는 50~100 사이의 숫자를 직전 값의 20% 정도 범위 내에서 변화시키면서 생성해줍니다. 이렇게 하면 심박수가 어제는 60이었는데 오늘은 100이어서 그래프가 갑자기 튀는 일은 생기지 않을 것입니다. 이러한 숫자의 집합을 생성해주는 API는 다소 골치아픈 코딩이 필요하기는 하지만 여전히 시간이 많이 걸리는 일은 아닙니다.
같은 형태로 문자, 단어, 문장, 날짜 등등을 임의로 생성해주는 메소드를 추가하면 아주 기본적인 형태의 데이터 생성 API는 쉽게 만들어줄 수 있습니다. 하지만 조금 더 사실적인 데이터 생성을 위하여 사전 정의된 데이터 중 하나를 임의로 뽑아주는 API도 만들 수 있을 것입니다. 예를 들어서 사람의 이름을 생성해주는 코드는 다음과 같이 작성될 수 있습니다.
public String getName(final int genderCode) {
switch (genderCode) {
case GENDER_CODE_FEMALE:
return femaleNames.pickOne();
case GENDER_CODE_MALE:
return maleNames.pickOne();
case GENDER_CODE_DONT_CARE: default:
if (RandomUtil.roll()) {
return englishFemaleMiddleNames.pickOne();
} else {
return englishMaleMiddleNames.pickOne();
}
}
}
여기에서 femaleNames, maleNames는 사전에 정의된 이름의 목록입니다. 목록에서 아무거나 하나 뽑아서 리턴해주는 메소드를 포함한 자료구조는 전혀 어렵지 않게 만들 수 있습니다. 하지만 문제는 정말 ‘아무거나’ 뽑아도 되느냐는 겁니다. 예를 들어서 이름이 아닌 성(Last name)을 하나 선택한다고 하겠습니다. 한국인의 21.6%는 김(金)씨이지만 허(許)씨는 0.7%에 불과합니다. 그런데 생성되는 데이터에 김씨와 허씨가 똑같은 비율로 나타난다면 그것도 그것 나름대로 현실적인 데이터가 아니라고 할 수 있습니다. 물론 성씨는 크게 중요하지 않은 문제일 수 있지만, 특정 비즈니스에서 임의의 데이터가 서로 다른 비중을 가지는 일은 꽤 중요해질 수도 있습니다. 때문에 해당 자료구조는 각각의 데이터마다 나타날 수 있는 확률을 가지고 있어야 되며, 개발자가 그 중 하나를 뽑았을 때 확률을 고려하여 뽑혀야 될 것 입니다.
비중을 고려하여 데이터를 뽑아내는 코드는 사실 그렇게 쉬운 일은 아닌데, 최근 SDS 개발자들의 알고리즘 실력이 일취월장 했으니까 지금 기준으로는 쉬운 일일지도 모르겠습니다. 어찌되었든 해당 구조에서 비중을 가지고 있는 데이터는 비중을 고려해서, 가지고 있지 않은 데이터는 그냥 일정한 확률로 뽑아서 반환해주면, 그 API를 사용하는 개발자는 어쩄든 하나 뽑아서 쓴다는 용도 자체는 동일하기 때문에 같은 API로 데이터를 생성할 수 있습니다.
String lastName = lastNames.pickOne();
이러한 식으로 API를 구성해주면 실제 개발자는 임의의 환자 데이터를 생성하기 위해 다음과 같은 형태의 코드를 작성할 수 있습니다.
PersonDataGenerator generator = PersonDataGenerator.getInstance();
Outpatient patient = new Outpatient();
patient.setGender(
RandomUtil.roll() ? Outpatient.Gender.MALE : Outpatient.Gender.FEMALE);
patient.setName(
generator.getEnglishName(
patient.getGender() == Outpatient.Gender.MALE ?
PersonDataGenerator.GENDER_CODE_MALE : PersonDataGenerator.GENDER_CODE_FEMALE));
patient.setAge(generator.getAge());
patient.setVisitType(
RandomUtil.roll() ? Outpatient.VisitType.INITIAL_VISIT : Outpatient.VisitType.FOLLOW_UP);
patient.setVisitReason(TextCore.generatePhrase());
patient.setBirth(generator.getBirthFromAge(patient.getAge()));
patient.setVisitAppointment(DateCore.generateTime(10));
이제 개발자는 무한하게 많은 테스트 데이터를 생성할 수 있게 되었습니다. ‘환자가 10,000명을 넘어가도 클라이언트가 느려지지 않을까?‘라는 의문에 테스트 DB에 데이터가 적다고 고민할 필요 없이 그저 for 문을 10,000번 돌아가게 바꾸는 것만으로도 테스트가 가능해지게 된 것 입니다. 반대로 ‘DB에 데이터가 하나도 없는 경우에도 제대로 표시될까?‘와 같은 의문 역시 DB를 건드리지 않고 테스트 해 볼 수 있습니다. 이렇게 진심이 없는 가짜 데이터를 활용하면, 대량의 데이터가 필요하다고 실제 운영DB에서 데이터를 가져와서 개인정보 문제를 발생시키지 않아도 된다는 점이 매우 매력적이었습니다. 실제 솔루션에서 가짜 데이터를 이용해 화면을 구성한 결과는 다음과 같습니다.
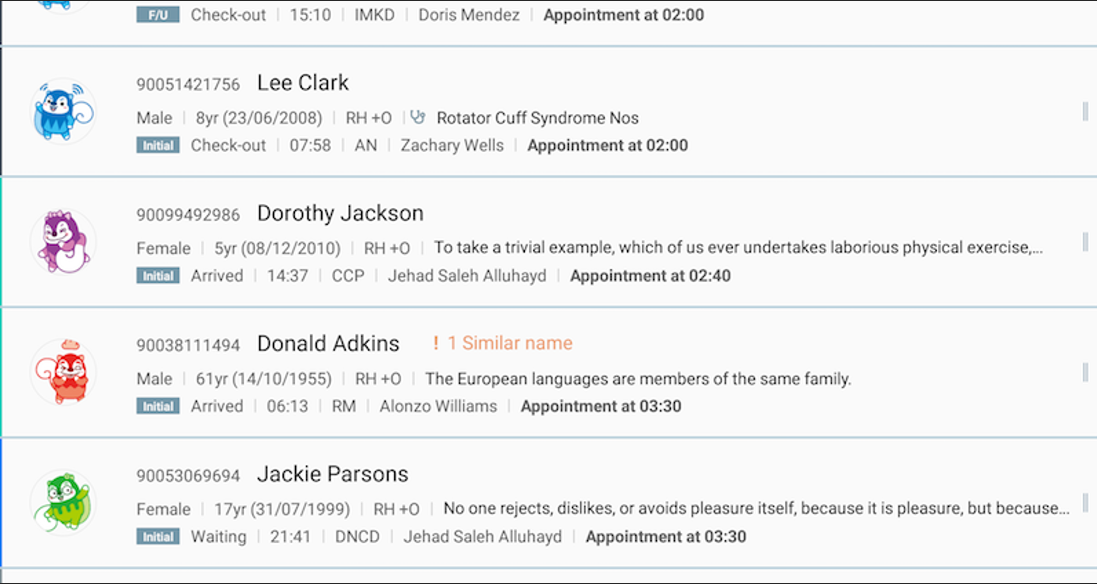
자세히 보면 조금 이상하지만 (예약이 새벽에 잡혀 있다거나..) 얼핏 보면 괜찮은 것 같은 데이터가 만들어졌습니다. 이러한 데이터 생성 기능은 추후 다른 글에서 다시 설명할 기회가 있을 Retrofit의 목업 네트워크 생성 기능과 결합되면 정말로 실제 데모 서버에 붙어 있는 듯한 효과를 솔루션이 스스로 낼 수 있도록 해주는데, 저희의 경우 서버 인터페이스가 개발되지 않았던 초반에 꽤 유용하게 사용하였고, 해외 지사에서 영업용 데모를 요청했을 때도 빌드를 다시 돌리는 정도만의 노력으로 대응할 수 있었습니다.
이벤트 기반 프로그래밍을 위한 메시지 버스
당시 저희가 계획하고 있던 솔루션은 뭔가 화면이 나오거나 하지는 않았지만, ‘안드로이드 태블릿용’이라는 기준은 정해져있는 상태였습니다. 항상 안드로이드 개발을 시작할 때는 액티비티를 주력으로 삼을지 프래그먼트를 주력으로 삼을지에 대해서 고민하기 마련이지만, 태블릿용 앱을 만든다고 가정하면 프래그먼트가 주력이 되는 것, 애초에 안드로이드에 프래그먼트라는 개념이 도입된 계기가 태블릿의 등장이었다는 점을 굳이 언급하지 않아도 너무나 자명한 일이었습니다. 그래서 저는 보통 안드로이드 개발을 시작할 때 하루나 이틀정도 고민하기 마련인 ‘Activity VS Fragment’의 난제를 5초만에 클리어하고 다음 고민을 하게 되었습니다. ‘그렇다면 그 많은 프래그먼트 사이의 메시지 교환은 어떻게 할 것인가?’
하나의 액티비티에 2개의 프래그먼트가 있다고 가정해보겠습니다. 태블릿 앱에서 가장 많이 나오는 형태인 하나의 목록과 하나의 상세화면이 있는 구조 입니다. 만약 왼쪽의 목록에서 아이템 하나를 선택하면 오른쪽의 상세화면에 상세 데이터가 표시되는 구조를 생각해볼 수 있습니다. 왼쪽의 목록에서 onItemClick 이벤트가 발생할 경우 왼쪽 프래그먼트가 그 결과를 핸들링합니다. 당연히 해당 목록에서 선택된 아이템이 위치, 데이터셋, 이벤트의 콜백 함수 모두 왼쪽 프래그먼트에 존재합니다. 오른쪽 프래그먼트의 경우 왼쪽의 선택에 따라 다른 상세화면을 표시해주게 됩니다. 보통 왼쪽 목록에서 가지고 있는 데이터만 가지고 상세화면을 표시하는 일은 없으니 왼쪽 목록에서 선택된 데이터의 ID 등을 받아와서 네트워크 호출을 진행하고, 그 응답 결과를 화면에 그려줄 것입니다.
chartList.setOnItemClickListener(
new AdapterView.OnItemClickListener() {
@Override
public void onItemClick(AdapterView<?> parent, View view, int position, long id) {
ChartItem item = items.get(position);
rightFragment.requestChart(item.getId());
}
}
);
대충 위와 같은 코드가 될 수 있습니다. 별로 어려울 것도 없고 큰 문제가 될 것도 없어보입니다. 하지만 사실 문제가 하나 있습니다. 왼쪽 프래그먼트가 오른쪽 프래그먼트, 그러니까 rightFragment를 가지고 있어야 된다는 점입니다. 만약 오른쪽 프래그먼트가 왼쪽 프래그먼트를 재조회하거나 하는 일이 생긴다면 오른쪽 프래그먼트도 왼쪽 프래그먼트를 들고 있어야 될텐데, 이런 경우 상호참조가 발생하게 됩니다. 상호참조로 인하여 발생할 수 있는 메모리 누수 등도 문제이지만, 서로 강하게 결합되어 버려서 떨어질 수 없는 상태가 되어버리는 것이 더 큰 문제일 수 있습니다. 프래그먼트를 굳이 분리하는 이유는 이런저런 상황에서 재사용도 하고 상속도 받고 하기 위함인데, 저렇게 서로가 서로를 들고 있으면 둘이 하나로 묶여서 취급받아야 되므로 하나의 액티비티에 다 그리는 것에 비해 장점은 별로 없고 단점은 그대로 받아오는 상황이 됩니다. 일반적으로 이런 케이스에서는 액티비티가 컨테이너 역할을 해주기 때문에, 액티비티가 메시지 전달자의 역할을 해주면 프래그먼트들의 상호 의존성을 조금 줄여볼 수 있습니다.
ChartItem item = items.get(position);
if (getActivity() instanceof ChartContainer) {
((ChartContainer) getActivity()).requestChart(item.getId());
}
물론 ChartConatiner라는 타입(보통은 인터페이스가 되겠지요)에는 requestChart 라는 메소드가 있을 것입니다. 그렇다면 컨테이너 역할을 하는 액티비티는 requestChart 메소드를 구현만 해주면 이 상황을 해결할 수 있습니다.
public void requestChart(String chartId){
if (rightFragment != null) {
rightFragment.showChart(chartId);
}
}
사실 엄청난 문제가 있는 것은 아니지만, 프래그먼트가 항상 액티비티의 레퍼런스를 가지고 있는 상황에서 액티비티가 프래그먼트의 레퍼런스를 가지는 것이 조금 불안하신 분은 (실제로 액티비티와 프래그먼트의 라이프사이클은 꽤 다른 주기를 가지기 때문에 이 상호참조도 그리 좋은 상황은 아닙니다.) 다음과 같이 코드를 작성할 수도 있습니다.
Fragment rightFragment = getFragmentManager().findFragmentById(R.id.rightFragment);
if (rightFragment != null) {
if (rightFragment instanceof ChartFragment) {
((ChartFragment) rightFragment).showChart(chartId);
}
}
이러한 해결책은 정석적인 방식의 메시지 전달에 가까우며, 컨테이너가 바뀌거나 프래그먼트가 서로 다른 곳에서 재사용 되는 경우에도 어느 정도 유연하게 대처할 수 있다는 점에서는 나쁜 디자인이 아닙니다. 가이드 하거나 실제로 코드를 작성하기도 크게 어렵지 않구요. 하지만, 여전히 프래그먼트와 액티비티들 사이에는 낮은 수준의 의존성이 존재합니다. 그리고 메시지의 발원지를 프래그먼트에 국한하지 않고 다양한 뷰, 스레드, 비즈니스 로직등으로 확장한다면 이와 같은 해결책도 뭔가 잘 안 맞아 떨어지는 것을 느낄 수 있습니다. 예를 들어서 다음 메소드가 백그라운드 스레드에서 돌아간다고 가정하겠습니다.
protected String doInBackground(Integer... params) {
int count = params[0];
long sum = 0;
for (int i = 0; i < count; i++) {
if (i > count / 2) {
Toast.makeText(context, "Hello!", Toast.LENGTH_SHORT).show();
}
sum += i;
SystemClock.sleep(500);
}
return "Sum : " + sum;
}
별 의미없는 계산을 백그라운드에서 매우 느리게 수행하다가 절반 정도 계산했을 때 화면에 메시지를 뿌리고자 합니다. Toast 메시지를 뿌리는 명령은 static 메소드 이기 때문에 큰 문제가 없어 보입니다만, 사실 이 코드는 돌아가지 않습니다.
Toast.makeText(context, "Hello!", Toast.LENGTH_SHORT).show();
토스트 메시지를 출력하는 makeText - show 메소드는 반드시 안드로이드 애플리케이션의 컨텍스트를 전달해줘야 되는데, 백그라운드 스레드에서는 컨텍스트에 접근할 수 없기 때문입니다. 이 문제를 해결하기 위해서 해당 백그라운드 태스크를 생성할 떄 context를 생성자등을 통해서 전달해줄 수 있습니다.
private Context context;
public BackgroundTest(Context context) {
this.context = context;
}
아쉽게도 이 방법은 잘못된 방법입니다. 백그라운드 태스크의 인스턴스가 컨텍스트를 붙잡고 있을 경우 모종의 이유로 태스크가 정상적으로 종료되지 않고 오랫동안 살아 있을 때 컨텍스트 역시 사라지지 않고 오랫동안 메모리에 남아있게 되는 문제점이 생길 수 있습니다. 보통 전달해주는 컨텍스트가 액티비티의 인스턴스인 경우가 많은데, 이 경우 액티비티가 메모리에서 사라지지 않는 부담감이 생기게 됩니다. 만약 토스트 메시지를 뿌려주는 정도가 아니라 액티비티나 프래그먼트 내부의 특정 메소드를 호출하거나 특정 UI객체에 직접 접근해서 뭔가 바꾸고자 하는 경우에는 어떨까요?
public BackgroundTest(Fragment myFragment) {
this.myFragment = myFragment;
}
@Override
protected void onPostExecute(String result) {
super.onPostExecute(result);
TextView textView = (TextView) myFragment.getView().findViewById(R.id.popup_title);
textView.setText(result);
}
이 코드의 위험성은 무엇일까요? 크게 2가지 정도 지적할 수 있을 것 같습니다. 첫번째로 백그라운드 스레드의 종료 후 결과를 포스팅 할 때 프래그먼트의 뷰 객체를 찾습니다. 이 시점에 myFragment는 null이 아닐 가능성이 매우 높습니다. 하지만 myFragment가 만약 다른 프래그먼트로 전환된 이후라면, 프래그먼트 내부의 뷰가 화면에서 사라진 이후라면 뷰 객체를 찾지 못해서 null pointer exception을 낼 가능성이 매우 높습니다. 이러한 케이스는 매우 흔하게 등장하는 케이스로, 예를 들어서 화면에 들어가서 네트워크 요청이 시작되었는데 바로 뒤로가기 등을 눌러서 뒤로 이동해버린 경우 네트워크 응답이 도착한 시점에 뷰가 사라져서 앱이 튕겨버리는 등의 문제가 발생할 수 있습니다.
다른 문제점은 위에서 말했던 것 처럼 백그라운드 태스크를 담당하는 클래스가 프래그먼트나 액티비티를 계속 붙잡고 있는다는 점입니다. 백그라운드에서 돌아가는 태스크들은 얼마든지 뷰 객체들보다 오랫동안 생존할 수 있고, 운이 없으면 영원히 끝나지 않을 수도 있습니다. 태스크들이 액티비티나 프래그먼트의 레퍼런스를 잡고 있으면 얼마든지 메모리 누수가 발생할 가능성이 있습니다. 물론 그렇다고 태스크가 뷰의 레퍼런스를 잡고 있는 모든 코드가 수정되어야 되는 코드라는 뜻은 아닙니다. 다만, 메모리 누수가 발생하지 않도록 뷰의 라이프사이클과 백그라운드 작업의 시작/진행/종료를 잘 맞춰야 될 필요가 있습니다. 하지만 많은 개발자들과 함께 일할때 ‘그러니까 메모리 누수 발생하지 않도록 조심하여 주시기 바랍니다.‘라고 가이드 하는 정도로 다들 조심해주기를 바라는 것은 지나친 바람입니다. 보나마나 우리의 프로젝트는 메모리 누수 같은 것은 신경쓸 수 없을 만큼 바쁠테니까요.
이러한 경우 해결책은 여러가지 있을 수 있습니다. 위와 같이 AsyncTask를 쓰는 경우 onProgressUpdate 메소드를 조금 더 복잡하게 정의해서 뷰에 지속적인 콜백을 줄 수도 있고, 핸들러를 정의하고 메시지 큐를 이용하여 스레드 간의 메시지 전달을 시도할 수도 있습니다. 실제로 이렇게 해결해야 되는 케이스도 있구요. 하지만 어이없을 정도로 훨씬 더 쉽고 더 강력한 방법을 써보겠습니다.
토스트 메시지를 출력할 때 일반적인 상황에서는 그냥 뿌리고자 하는 메시지만 전달해주고 싶어합니다. 위에서 보셨듯이 안드로이드의 Toast 클래스는 static으로 정의되어 있어서 어느 시점에도 사용할 수는 있지만, 컨텍스트를 전달해야 되는 어려움이 있으니 개발자들이 다음과 같은 형태로 토스트 메시지를 출력할 수 있다면 참 좋을 것 같습니다.
NewToast.show("Hello!");
이러한 코드를 사용할 수 있도록 하기 위해서는 간단히 보면 NewToast 클래스가 액티비티를 static하게 가지고 있으면 못 만들 것은 없어 보입니다. 하지만 액티비티에 대한 정적 참조는 많은 재앙을 불러올 수 있습니다. 물론 단순한 토스트 메시지 출력을 위해서는 애플리케이션 컨텍스트(Application Context)를 쓰면 쉽게 해결이 가능하지만 일단은 그 해결책은 제외하고 다른 방법을 생각해보겠습니다.
NewToast 클래스의 show 메소드를 다음과 같이 정의하겠습니다.
public static void show(String message) {
EventCenter.post(new ToastEvent(message));
}
코드 자체는 간단하지만 이 짧은 코드에도 알 수 없는 부분이 몇 몇 보입니다. EventCenter 클래스, post 메소드, ToastEvent 클래스가 그것인데요, ToastEvent 클래스는 다음과 같습니다.
public class ToastEvent {
String message;
public ToastEvent(String message) {
super.message = message;
}
}
ToastEvent 클래스는 message 라는 문자열 하나만을 담고 있는 아주 평범한 자바 클래스 입니다. 이 클래스의 내용은 전혀 특별할 것도, 신경쓸 것도 없습니다. 다만 신경써야 될 것은 클래스의 타입 그 자체입니다. 액티비티에 다음과 같은 메소드가 정의되어 있다고 가정해보겠습니다.
@Subscribe
public void showToastMessage(ToastEvent event) {
Toast.makeText(this, event.message, Toast.LENGTH_SHORT).show();
}
이 메소드의 내용 자체는 전달된 객체의 message 문자열을 이용하여 토스트 메시지를 출력해주는 지극히 단순한 코드입니다. 이 메소드는 파라메터로 ToastEvent라는 클래스의 인스턴스를 받게 되어 있는데, 이 점이 중요합니다. 최초의 코드를 다시 살펴보면
EventCenter.post(new ToastEvent(message));
이와 같은 코드로 메시지를 출력했는데, 감이 좋으신 분이라면 저 때 post 안에 들어갔던 ToastEvent 클래스의 인스턴스가 액티비티의 showToastMessage의 인자로 전달될 것 같다고 생각하실 수 있을 것입니다. 실제로 그렇습니다. 메시지를 보내는 위치는 프로젝트 소스코드 내의 어떤 곳이라도 상관 없습니다. 그것이 프래그먼트이거나, 액티비티이거나, 뷰 객체 내부 이거나, 비즈니스 로직을 수행하는 중간이거나, 심지어 VO 클래스에서 toString 메소드 이내이더라도 전혀 상관 없습니다. 해당 코드가 실행되는 시점에 이벤트를 발생시킵니다. 그리고 발생한 이벤트는 @Subscribe 라는 어노테이션을 구현했으며 발생한 이벤트와 같은 타입의 파라메터를 받는 모든 메소드를 실행시켜 줍니다. 이벤트의 타입 자체가 중요하므로 내용물은 필요에 의해서 마음껏 다르게 구현할 수 있습니다. 예를 들어서 토스트 이벤트를 발생시킬 때 토스트 메시지의 지속시간을 조절하고 싶다면 ToastEvent에 duration 필드를 추가해주면 되는 것입니다.
이러한 코드를 가능하게 만들어주는 것이 EventBus 입니다. 안드로이드가 아닌 다른 플랫폼들에서도 종종 보이는 패턴인데, 안드로이드의 경우 플랫폼에서 바로 지원하지는 않지만 오픈소스를 이용하여 기능을 구현할 수 있습니다. GreenRobot의 EventBus, Square의 Otto 등이 대표적인 이벤트 버스 기능을 지원해주는 오픈소스 라이브러리이며, 제 경우에는 Otto를 사용하였습니다.
이벤트 버스의 가장 큰 장점은, 이벤트의 생산자(Producer)와 구독자(Subscriber) 사이에 아무런 의존성이 존재하지 않는다는 것입니다. 의존성이 약하다는 뜻이 아닙니다. 의존성이 전혀 없습니다. 예를 들어서 위 코드에서 showToastMessage 역할을 수행하는 액티비티가 모종의 사유로 인해서 없어졌다고 가정하겠습니다. 일반적인 구현에서는 운이 좋은 경우 컴파일 오류가 나고, 다른 액티비티 등에 해당 메소드를 새로 만들어주는 정도로 해결될 수 있겠지만, 운이 나쁜 경우에는 런타임 에러를 낼 수도 있고 수정이 복잡해지는 경우도 있습니다. 하지만 이벤트 버스를 사용하는 경우 Subscribe 하는 메소드가 존재하지 않는다면 그저 이벤트 호출 자체가 무시될 뿐 아무런 오류도 발생시키지 않습니다. 반대로 새로운 액티비티나 프래그먼트를 만드는 경우에도 해당 이벤트를 받고 싶다면 그저 @Subscribe 메소드를 추가해주면 될 뿐 특정 객체와 연결시키거나 뭔가를 등록시킬 필요가 전혀 없습니다.
조금 더 현실적인 이점을 보여드리기 위해서, 이벤트 버스를 실제 코드에서 구현한 사례를 보여드리겠습니다. 저희는 푸시를 보내고 받기 위해서 SDS 사내의 푸시 솔루션을 사용하였는데, 해당 솔루션의 경우 푸시 메시지가 디바이스에 도착하면 별도로 구현한 핸들로의 다음 메소드를 호출해줍니다.
@Override
public void handleReceivedString(String message, String messageId) {
// (전략)
EventCenter.post(new PatientCheckInEvent());
}
푸시 메시지를 확인하고, 만약 ‘환자가 새로 체크인 했다’라는 푸시인 경우 이벤트 버스에 PatientCheckInEvent를 보내도록 코드를 작성하였습니다. 저희 솔루션의 경우 환자가 체크인 했을 때 처리해야 되는 클라이언트 로직이 조금 복잡한 편이었는데, 현재 화면이 초기 목록 화면인 경우 뭔가 굉장히 화려한 배너를 슬라이드 해서 화면에 보여주어야 됐고, 현재 다른 환자를 검진하고 있는 중이라면 간단한 토스트 메시지를 출력해줘야 됐습니다. 그러면서 동시에 상단의 툴바는 현재 체크인 된 환자의 카운트를 더해서 표시해주어야 했습니다. 이 경우 초기화면의 프래그먼트에서는
@Subscribe
public void patientCheckIn(PatientCheckInEvent event) {
// 화려한 배너를 띄워준다...
}
위와 같이 작성하고, 검진화면 프래그먼트에서는
@Subscribe
public void patientCheckIn(PatientCheckInEvent event) {
// 토스트 메시지를 뿌려준다...
}
위와 같이 작성하면 됩니다. 이와 같은 작성하면 위에서 말씀드렸던 것 처럼, 요구사항이 바뀌어서 (SDS에서는 매우 자주 있는 일입니다) 갑자기 어디서는 더 이상 토스트 메시지를 출력하지 말아라..라고 하더라도 그 변경범위가 ‘어디서’에 제한될 뿐 핸들러를 고치거나 하지는 않아도 됩니다. 심지어 특정 케이스에서 푸시 자체가 제거되더라도 위 메소드들을 제거할 필요가 없습니다. 영원히 호출되지 않는 메소드가 될 뿐, 아무 문제가 발생하지 않습니다. 특정 요구사항의 변경에도 변경범위가 최소화 되고 사이드 이펙트가 줄어드는 것이 가장 큰 장점입니다.
다른 장점으로는 공통화 된 기능 제공과 가이드가 엄청나게 쉬워진다는 것입니다. 예를 들어서 안드로이드에서 키보드가 나타나고 사라지는 것을 감지하기 위해서는 다음과 같은 코드를 사용하여야 합니다.
감지하고자 하는 액티비티나 프래그먼트의 뷰에 다음과 같이 글로벌 옵저버를 추가합니다.
public void attachToView(View view) {
keyboardThreshold = (int) TypedValue.applyDimension(
TypedValue.COMPLEX_UNIT_DIP, DP_KEYBOARD_THRESHOLD,
view.getResources().getDisplayMetrics());
this.view = view;
currentHeight = view.getHeight();
view.getViewTreeObserver().addOnGlobalLayoutListener(this);
if (currentHeight <= 0) {
view.getViewTreeObserver().addOnPreDrawListener(this);
}
}
그리고 onGlobalLayout 콜백을 다음과 같이 작성해줍니다.
@Override
public void onGlobalLayout() {
int newHeight = view.getHeight();
if (currentHeight > 0) {
int diff = newHeight - currentHeight;
if (diff < -keyboardThreshold) {
// keyboard is show
isKeyboardShown = true;
if (listener != null)
listener.onKeyboardShow(-diff);
} else if (diff > keyboardThreshold) {
// keyboard is hide
isKeyboardShown = false;
if (listener != null)
listener.onKeyboardHide(diff);
} else {
}
}
currentHeight = newHeight;
}
위와 같은 형태로 키보드가 나타나는 순간, 사라지는 순간을 캐지할 수 있습니다.
라고 가이드하는 것과,
키보드가 나타날 떄는 KeyboardVisibilityEvent.Show 이벤트를 보내드릴테니 필요하시면 Subscribe 해서 사용하세요.
사라질때는 .Hide 이벤트가 발생합니다.
라고 가이드 하는 것 사이의 차이는 어마어마합니다. 저런 식으로 특정 케이스에 콜백되는 형태의 호출이 필요한 경우 많은 이득을 취할 수 있습니다.
여기까지만 보면, 오픈소스 하나 추가한 것 외에는 직접 준비단계에서 코드나 라이브러리를 만든 것이 없어 보이는데, 사실 Otto를 이용하여 안드로이드에서 이벤트 버스를 구성하는 방식에는 한가지 문제가 있습니다. 이벤트 버스는 스레드를 넘나들면서 이벤트를 전달하지는 않는다는 것입니다. 쉽게 말해서 이벤트 버스는 같은 스레드 사이에서만 통로가 열리고, 다른 스레드로 전달된 이벤트는 전달을 보장하지 않습니다. 이 경우 화면에서 화면으로 메시지 전달은 같은 UI스레드에서 전달되는 것이니까 별 문제가 없지만, 위에서 처럼 별도의 푸시 핸들러, 비즈니스 로직을 수행하는 중간과 같이 UI스레드에서의 발행이 보장되지 않는 곳에서의 전달은 문제를 일으킬 수 있습니다.
사실 안드로이드 개발에 익숙하신 분들은 핸들러(Handler), 메시지 큐(Message Queue), 루퍼(Looper)의 개념에 대해서 알고 계시기 때문에 이러한 문제가 발생했을 때 비교적 능숙하게 문제를 해결할 수 있습니다. ‘메인루퍼를 이용해서 메인 핸들러를 가져온 다음 이벤트를 메인 스레드에 강제로 포스팅 해주면 백그라운드 에서 메인 스레드로 이벤트를 넘길 수 있겠구나’와 같이요. 하지만 안드로이드를 처음 접하는 사람들은 저 문장에서 모르는 단어가 최소 3개 이상은 나오고 있으니 저 정도 가이드로는 문제를 해결했다고 하기 어렵습니다. 따라서 별도의 이벤트 관리 클래스를 만들어 주고 다음과 같은 메소드를 만들어서 제공해줍니다.
private static final Handler mainThread = new Handler(Looper.getMainLooper());
public static void postToMainThread(Object... events) {
if (events == null) {
return;
}
for (final Object event : events) {
mainThread.post(new Runnable() {
@Override
public void run() {
bus.post(event);
}
});
}
}
이벤트를 포스팅 할 때 해주어야 될 동작을 공통화 시켰습니다. 사실 Otto는 이런 경우 사용하라고 ThreadEnforcer 클래스와 API를 제공해주기는 하는데, 제가 테스트 해봤을 때는 원하는만큼 잘 동작하지는 않아서 부득이하게 별도의 포스팅 메소드를 작성하게 되었습니다. 이와 같은 API는 조금만 더 생각하면, 전달되는 이벤트 객체에 다음과 같이 UI쪽으로 전달되어야 되는 메소드임을 명시해주면,
@UIEvent
public class KeyboardVisibilityEvent {
}
다음과 같이 하나의 post 메소드에서 어노테이션을 구분하여 메소드를 동일 스레드 혹은 UI 스레드로 포스팅 하도록 자동으로 나누어 줄 수 있습니다.
public static void post(Object... events) {
if (events == null) {
return;
}
for (Object event : events) {
if (event == null) {
continue;
}
if (event.getClass().isAnnotationPresent(UIEvent.class)) {
postToMainThread(event);
} else {
bus.post(event);
}
}
}
이와 같은 코드 작성은, 보통 개발자가 이벤트 클래스를 생성할 때만 UI스레드로 가야될 지 일반적인 스레드로 포스팅해야 될 지 구분해주면 다른 로직을 작성하다가 중간에 이벤트를 포스팅해야 될 때는 굳이 구분을 해주지 않아도 정상적인 스레드로 이벤트가 포스팅 될 수 있도록 도와줍니다. 특히나 이벤트 버스를 사용하는 프로그래밍의 경우 디버깅이 쉽지 않고 스레드 간의 메시지 동기화가 잘 안되는 문제는 예상치 못한 동작을 많이 불러오기 떄문에 이렇게 정적으로 스레드를 구분해주는 것이 좋습니다.
이벤트 버스의 사용이 무조건 장점만 있는 것은 아닌데, 이벤트 버스를 기반으로 프로그래밍 할 경우 비록 그것이 콜백되는 형태의 호출이기는 하지만 너무 많이 사용하면, 특히 비즈니스 로직의 중간에 자꾸 사용될 경우 이벤트 버스는 일종의 GoTo문과 비슷한 형태로 동작하게 됩니다. 심지어 정적인 의존성을 가지지 않는다는 장점은 반대로 말하면 정적인 타이밍에는 어디서 이벤트를 받아내는지 확인하기도 어려워서 IDE 상에서 특정 이벤트의 발행이 어떤 구독자로 연결되는지 알아내기 어렵다는 문제점을 가지게 됩니다. 특히나 인터페이스 기반으로 연결하는 것이 귀찮아서 이벤트 만을 이용하여 메시지를 전달하는 경우 타인이 볼 때 코드 흐름을 알아내기 어렵다는 단점을 가지게 됩니다.
때문에 가급적이면 이벤트 버스를 이용한 프로그래밍은 ‘불특정 다수에게 메시지를 전달하는 경우’에 적극적으로 사용하고, ‘특정한 화면에 메시지를 전달하는 경우’에는 고전적인 방식을 그대로 사용하는 것이 여러가지 측면에서 유리합니다. 일반적인 프로젝트인 경우 공통 클래스, 모듈, 라이브러리 등에서 이벤트 버스를 사용하고 업무 화면에서는 사용을 지양하는 쪽으로 가이드해도 괜찮을 것 같습니다.
복잡한 화면 내비게이션 컨트롤 가이드 하기
앞에서 언급했던 것 처럼, 이 솔루션은 태블릿에서만 돌아가는 것을 전제로 하고 있기 때문에 앱이 기본적으로 여러개의 액티비티를 기반으로 하는 것이 아니라 여러개의 프래그먼트를 기반으로 이루어지도록 구성하는 것은 큰 어려움 없이 결정할 수 있었습니다. 문제는 이 앱이 일반적인 프래그먼트 기반의 구성으로 커버가 될 만한 수준의 복잡도를 가지고 있느냐는 것이었습니다.
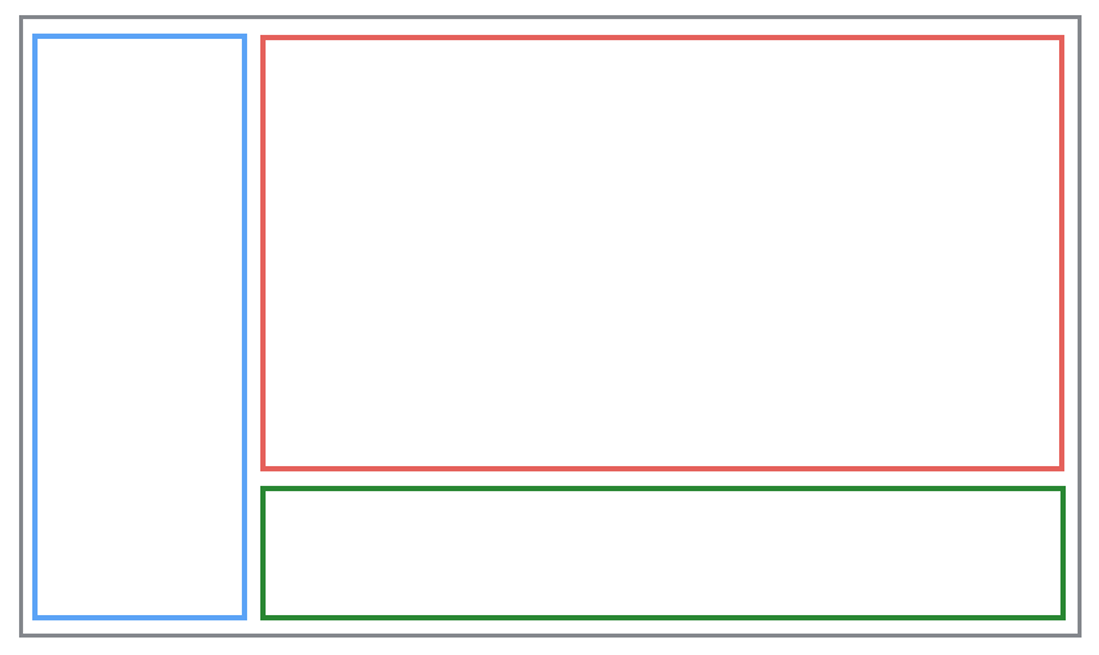
태블릿 앱에서 나올 수 있는 일반적인 레이아웃 구성 중 하나 입니다. 개발을 준비하는 입장에서는 레이아웃이 다 이런 식이기만 하면 행복할 수 밖에 없습니다. 하나의 액티비티 (검은색)에 적당한 레이아웃을 구성하여 3개의 컨테이너를 배치하고 그 안 쪽에 프래그먼트들을 배치할 수 있도록 API를 마련해주면 됩니다. 경우에 따라서는 특정 프래그먼트가 커지거나 사라지거나 할 수 있도록 지원해주면 완벽합니다.
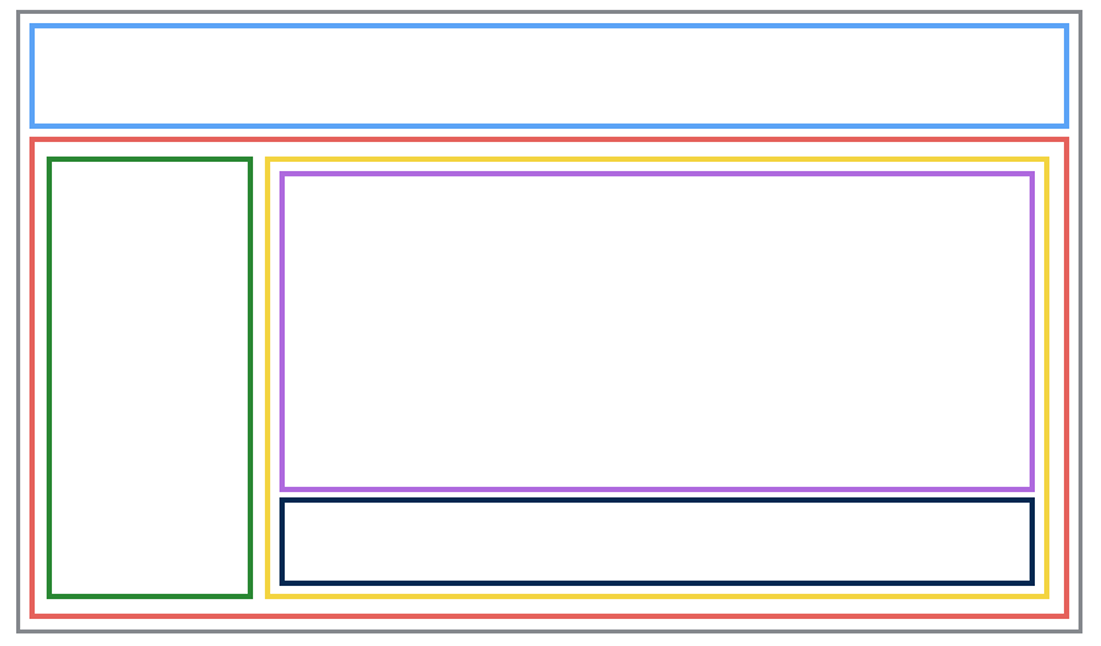
이런 레이아웃은 어떤가요? 심지어 이런 레이아웃이 상황에 따라 어떤건 커지고 어떤건 작아지고 어떤건 사라지고 어떤건 생기고 그래야 된다면? 저 중 일부는 탭이고 일부는 스크롤 가능하고 일부는 항상 떠있고 일부는 계속 변한다면? 액티비티에 레이아웃은 어떤 식으로 배치하고 어떤 식으로 컨트롤해야될지 매우 까마득한 상황입니다. 가장 까마득한 점은 준비하던 당시에는 화면과 관련된 어떤 정보도 없었기 때문에 저 정도로 복잡한 레이아웃이 매우 다양한 형태로 ‘나올 수도 있다’를 가정하고 준비해야 된다는 점이었습니다.
다행히도 안드로이드에는 Nested Fragment라는 요소가 있습니다. 일반적인 인식과는 다르게 안드로이드는 프래그먼트 안에 프래그먼트를 배치하지 못하는데, 4.2 버전에 부터는 그 기능이 Nested Fragment라는 이름으로 제공되었습니다. Nested Fragment의 사용은 매우 간단합니다.
getChildFragmentManager()
.beginTransaction()
.add(R.id.container_result,new ResultFragment())
.commit();
안드로이드 4.2 버전에서 부터는 프래그먼트에 getChildFragmentManager() 라는 메소드가 생겼는데, 이 메소드가 반환하는 타입은 FragmentManager이기 때문에 기존 액티비티에서 프래그먼트를 다루는 것과 완전히 동일한 방식으로 프래그먼트가 프래그먼트를 다룰 수 있습니다. 프래그먼트를 배치하거나 찾거나 지우거나 모두 액티비티와 같은 수준으로 가능합니다. 즉, 위와 같이 매우 복잡하게 중첩되는 레이아웃도 정신만 똑바로 차리면 못 만들 것이 없다는 뜻이 됩니다. 심지어 사용법도 동일하기 때문에 우리 앱의 최소 버전이 4.2(API Level 17) 이상만 되면 모든 것이 완벽할 것 같았습니다. 그리고 저희 앱의 최소 버전은 5.0 이었습니다. 모든 것이 완벽했습니다.
하지만 실제로 코드를 작성하고 샘플을 만들어보면서 모든 것이 불완전해지기 시작했습니다. 결론부터 말씀드리면 안드로이드의 Nested Fragment는 개발자들에 대한 인간적이 존중이 매우 부족한 프로젝트들 처럼 겉으로는 잘 돌아가는 것 처럼 보여도 속으로는 엄청난 문제점을 쌓아두고 있었습니다. 뭔가 문제 하나가 생겨서 인터넷을 뒤져보면 “Nested Fragment 쓰지 말아라.” 라든지 “아니 구글 너네는 내가 2년 전에 버그 리포트 했는데 아직도 안 고치냐.” 같은 글을 쉽게 볼 수 있었으니까요. 프래그먼트를 새로 배치하거나 변경할 떄의 State 문제, 백스택에서 프래그먼트를 빼낼 때 ‘가끔’ 예외가 발생하기도 하고, 프래그먼트의 리테인 설정이 꼬이는 문제에, 애니메이션은 뜬금 없이 사라져버리고 등등, 방송을 보니까 구글에는 프로페셔널한 개발자들이 넘쳐난다는데 왜 이런 문제들이 생길까 이해가 되지 않았습니다.
안드로이드 자체의 버그와 불완정성을 제외하고서라도, 중첩된 프래그먼트가 가지는 개념적인 문제점이 있습니다. 예를 들어보겠습니다.
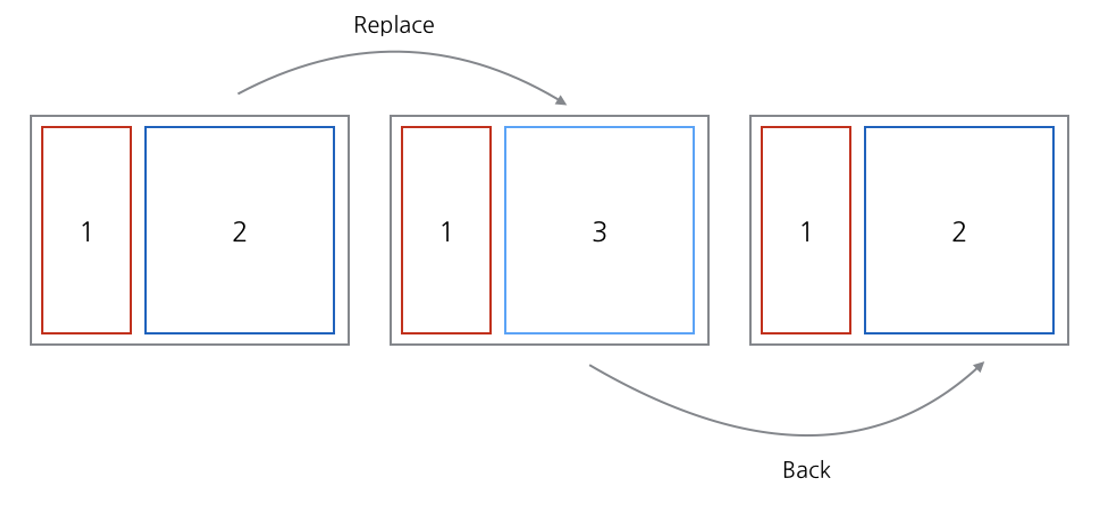 
위와 같이 중첩되지 않은 평이한 프래그먼트 배치의 경우 일반적으로 네비게이션의 대상이 되는 주 프래그먼트(Main fragment)가 존재하며 2번 프래그먼트에서 3번 프래그먼트로 이동하는 경우 처럼 주 프래그먼트 영역에 변경되는 경우에만 프래그먼트 매니저의 백 스택(Back stack)에 프래그먼트를 추가해주면 3번 프래그먼트가 떠있는 상태에서 뒤로가기 버튼을 누르더라도 별다른 혼란 없이 2번 프래그먼트로 돌아올 수 있습니다. 백 스택에 프래그먼트가 무한히 쌓여 메모리 초과를 발생시킬 위험만 적절히 커트해주면 됩니다.

위와 같이 중첩되지 않은 평이한 프래그먼트 배치의 경우 일반적으로 네비게이션의 대상이 되는 주 프래그먼트(Main fragment)가 존재하며 2번 프래그먼트에서 3번 프래그먼트로 이동하는 경우 처럼 주 프래그먼트 영역에 변경되는 경우에만 프래그먼트 매니저의 백 스택(Back stack)에 프래그먼트를 추가해주면 3번 프래그먼트가 떠있는 상태에서 뒤로가기 버튼을 누르더라도 별다른 혼란 없이 2번 프래그먼트로 돌아올 수 있습니다. 백 스택에 프래그먼트가 무한히 쌓여 메모리 초과를 발생시킬 위험만 적절히 커트해주면 됩니다.
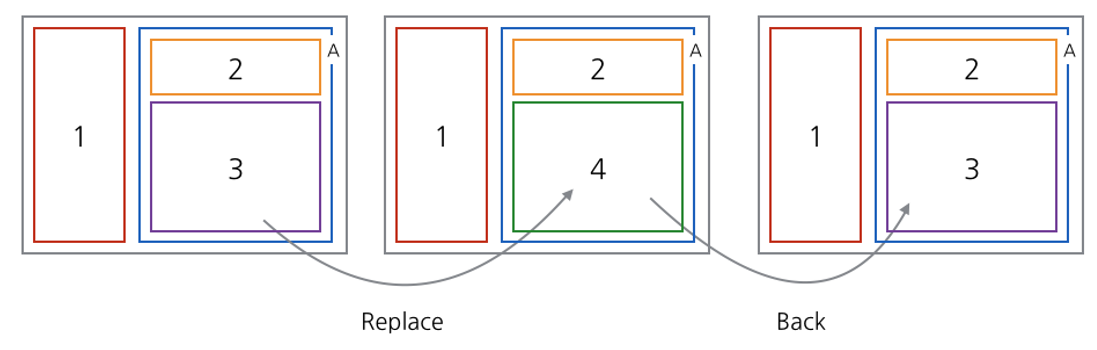 
2번 프래그먼트와 3번 프래그먼트를 감싸고 있는 프래그먼트를 A 프래그먼트라고 하겠습니다. 이와 같은 레이아웃에서는 최초 3번 프래그먼트가 배치된 영역이 일종의 주 프래그먼트 영역을 담당하고 있어서 특정 이벤트로 인하여 네비게이션이 발생했을 때 3번 프래그먼트가 4번 프래그먼트로 전환되었다고 가정하겠습니다. 이 때 디바이스의 뒤로가기 버튼을 누를 경우 4번 프래그먼트가 3번 프래그먼트로 돌아가는 것이 타당해보입니다. 레이아웃만 약간 복잡할 뿐 중첩 프래그먼트를 사용하지 않는 경우와 크게 다를 것이 없어 보입니다.

2번 프래그먼트와 3번 프래그먼트를 감싸고 있는 프래그먼트를 A 프래그먼트라고 하겠습니다. 이와 같은 레이아웃에서는 최초 3번 프래그먼트가 배치된 영역이 일종의 주 프래그먼트 영역을 담당하고 있어서 특정 이벤트로 인하여 네비게이션이 발생했을 때 3번 프래그먼트가 4번 프래그먼트로 전환되었다고 가정하겠습니다. 이 때 디바이스의 뒤로가기 버튼을 누를 경우 4번 프래그먼트가 3번 프래그먼트로 돌아가는 것이 타당해보입니다. 레이아웃만 약간 복잡할 뿐 중첩 프래그먼트를 사용하지 않는 경우와 크게 다를 것이 없어 보입니다.
하지만 두 레이아웃 사이에는 큰 차이가 하나 있습니다. 뒤로가기 버튼을 눌러서 4번에서 3번으로 이동할 때 돌아가야 될 프래그먼트 정보는 마찬가지로 백 스택에 존재하는데, 문제는 그 백 스택이 Child Fragment Manager의 백 스택이라는 점 입니다. 즉 뒤로가기를 눌렀을 때 반응해야 될 백스택은 액티비티 혹은 가장 바깥쪽 프래그먼트의 프래그먼트 매니저에 존재하지 않고 프래그먼트 A를 뒤져봐야 합니다. 뒤로가기 버튼이 눌렸을 때 이벤트는 액티비티가 핸들링 하기 때문에 액티비티는 프래그먼트 A의 존재를 알고 해당 프래그먼트에 뒤로가야 된다는 정보를 전달해 줄 필요가 있습니다.
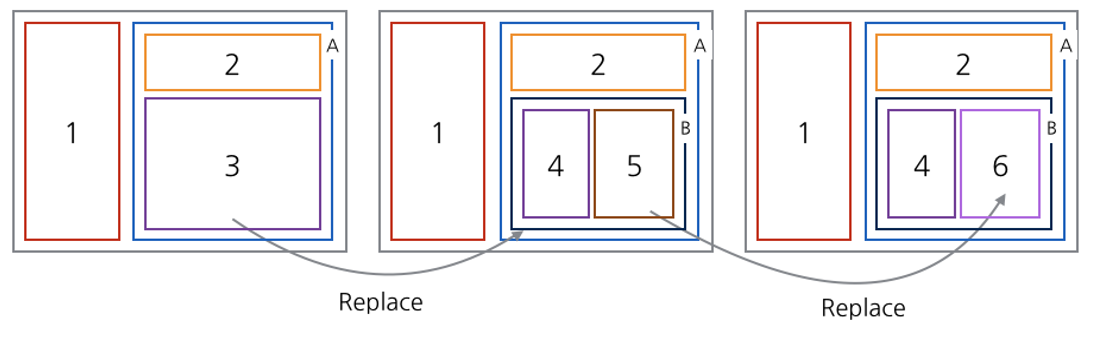 
조금 더 끔찍한 케이스를 예로 들어보겠습니다. 최초의 프래그먼트 배치는 동일합니다. 여기에서 네비게이션이 발생하여 3번 프래그먼트가 다시 중첩 프래그먼트의 컨테이너인 프래그먼트 B로 전환되었습니다. 이제 프래그먼트 A는 프래그먼트 2와 프래그먼트 B를 가집니다. 그리고 프래그먼트 B는 다시 프래그먼트 4와 프래그먼트 5를 가지게 됩니다. 이 때 주 프래그먼트 컨테이너는 5번 프래그먼트의 컨테이너로 전환되어, 다시 네비게이션이 발생했을 때 프래그먼트 5는 프래그먼트 6으로 전환 됩니다.
자, 이 시점에서 뒤로가기 버튼을 눌렀습니다. 그렇다면 네비게이션은 어떤 식으로 전환되어야 될까요? 뒤로가기는 네비게이션의 반대라고 생각한다면 일반적으로 원하는 동작은 다음과 같습니다.

조금 더 끔찍한 케이스를 예로 들어보겠습니다. 최초의 프래그먼트 배치는 동일합니다. 여기에서 네비게이션이 발생하여 3번 프래그먼트가 다시 중첩 프래그먼트의 컨테이너인 프래그먼트 B로 전환되었습니다. 이제 프래그먼트 A는 프래그먼트 2와 프래그먼트 B를 가집니다. 그리고 프래그먼트 B는 다시 프래그먼트 4와 프래그먼트 5를 가지게 됩니다. 이 때 주 프래그먼트 컨테이너는 5번 프래그먼트의 컨테이너로 전환되어, 다시 네비게이션이 발생했을 때 프래그먼트 5는 프래그먼트 6으로 전환 됩니다.
자, 이 시점에서 뒤로가기 버튼을 눌렀습니다. 그렇다면 네비게이션은 어떤 식으로 전환되어야 될까요? 뒤로가기는 네비게이션의 반대라고 생각한다면 일반적으로 원하는 동작은 다음과 같습니다.
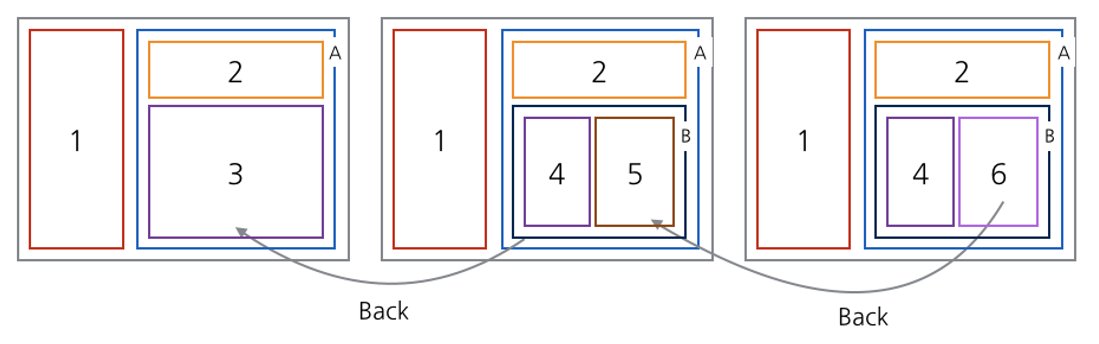 
문제는 뒤로가기 버튼이 2번 눌렸을 때 앱 내부에서 일어나야 되는 처리입니다. 오른쪽 끝의 프래그먼트 배치에서 뒤로가기 버튼이 눌렸을 때 반응해야 되는 것은 프래그먼트 B의 프래그먼트 매니저 입니다. 프래그먼트 B의 백 스택에는 프래그먼트 5가 쌓여있을 것이기 때문에 프래그먼트 5를 복구시켜주고 뒤로가기 처리를 끝낼 수 있습니다. 그런데 이 때 뒤로가기 버튼이 한 번 더 눌린다면 이 때 반응해야 되는 것은 프래그먼트 A의 프래그먼트 매니저 입니다. 여전히 프래그먼트 B가 화면에 존재하고 프래그먼트 B의 프래그먼트 매니저도 건재하지만, 프래그먼트 B의 프래그먼트 매니저는 백 스택이 비어있는 상태이기 때문에 프래그먼트 A로 뒤로가기 동작을 올려보내고, 프래그먼트 A는 백 스택에 프래그먼트 3이 존재하기 때문에 프래그먼트 3을 꺼내줄 수 있습니다. 이러한 뒤로가기 동작의 전파가 액티비티로 부터 최하위 중첩 프래그먼트 컨테이너까지 전달되었다가 다시 처리하지 못한 동작이 액티비티 까지 올라간다면 액티비티는 이전 액티비티로 이동하거나, 앱을 종료시키거나 할 수 있을 것입니다.

문제는 뒤로가기 버튼이 2번 눌렸을 때 앱 내부에서 일어나야 되는 처리입니다. 오른쪽 끝의 프래그먼트 배치에서 뒤로가기 버튼이 눌렸을 때 반응해야 되는 것은 프래그먼트 B의 프래그먼트 매니저 입니다. 프래그먼트 B의 백 스택에는 프래그먼트 5가 쌓여있을 것이기 때문에 프래그먼트 5를 복구시켜주고 뒤로가기 처리를 끝낼 수 있습니다. 그런데 이 때 뒤로가기 버튼이 한 번 더 눌린다면 이 때 반응해야 되는 것은 프래그먼트 A의 프래그먼트 매니저 입니다. 여전히 프래그먼트 B가 화면에 존재하고 프래그먼트 B의 프래그먼트 매니저도 건재하지만, 프래그먼트 B의 프래그먼트 매니저는 백 스택이 비어있는 상태이기 때문에 프래그먼트 A로 뒤로가기 동작을 올려보내고, 프래그먼트 A는 백 스택에 프래그먼트 3이 존재하기 때문에 프래그먼트 3을 꺼내줄 수 있습니다. 이러한 뒤로가기 동작의 전파가 액티비티로 부터 최하위 중첩 프래그먼트 컨테이너까지 전달되었다가 다시 처리하지 못한 동작이 액티비티 까지 올라간다면 액티비티는 이전 액티비티로 이동하거나, 앱을 종료시키거나 할 수 있을 것입니다.
이렇게 복잡한 레이아웃을 가정하는 것은 일종의 노파심이나 편집증에 해당한다고 볼 수도 있겠지만 사실 실제로 저희가 개발한 솔루션은 더 복잡했습니다. 단순히 프래그먼트의 전환과 뒤로가기 정도만 처리하는 것이 아니라 위 그림의 프래그먼트 B 쯤에 해당하는 곳에 탭 컨테이너가 존재하고 뒤로가기 버튼을 눌렀을 때 탭 이동의 히스토리를 따라서 이전 탭으로 이동해야 된다는 요구사항까지 있었습니다. 특히나 태블릿의 경우 스마트 폰에 비하여 디자인과 레이아웃의 제약이 비교적 적기 때문에 오히려 복잡한 화면 구성에 대응해야 되는 어려움이 있었습니다.
이러한 어려움을 해결하기 위해서 디수의 프래그먼트 매니저를 관리할 별도의 매니저 클래스를 작성할 필요가 있었는데, 이 매니저 클래스는 액티비티 혹은 컨테이너 프래그먼트 들에 하나씩 주어지고 (즉, 프래그먼트 매니저를 가지고 있는 UI 객체들에게 하나씩 주어지고) 해당 화면에서 뒤로가기 동작을 컨트롤 할 주 프래그먼트 영역을 담당하는 프래그먼트를 별도의 인터페이스로 분리한 뒤, 프래그먼트를 배치할 때 컨테이너 프래그먼트가 배치될 경우 해당 프래그먼트의 레퍼런스를 가지고 있다가 뒤로가기 동작이 일어났을 때 해당 이벤트를 전파 시키고 결과를 다시 받아오도록 구성하였습니다.
public boolean notifyBackPressed() {
if (rewindableContainer != null) { // 하위 컨테이너가 있으면!
if (rewindableContainer instanceof LessorContainer) { // 하위 컨테이너가 또 하위 컨테이너를 가지고 있을 수 있다면!
Lessor childLessor = ((LessorContainer) rewindableContainer).getLessor(); // 하위 컨테이너의 Lessor를 가져와보고!
if (childLessor != null) { // 하위 컨테이너가 정말로 Lessor를 가지고 있으면!
if (childLessor.notifyBackPressed()) { // 뒤로 가보라고 찔러본다.
return true; // 그냥 한 번 시켜봤는데 정말로 뒤로 갔으면 거기서 끝낸다.
}
}
}
return rewindableContainer.rewind(); // 하위 컨테이너가 있는데 또 하위 컨테이너를 가지고 있지 않거나 뒤로가기 동작에서 걔(하위의 하위)가 아무것도 안했으면 하위 컨테이너의 리와인드를 호출하는 선에서 끝낸다.
} else {
return false; // 하위 컨테이너가 없으면 여기선 뒤로가기를 처리할 것이 없다. 상위 컨테이너한테 책임을 넘긴다.
}
}
이와 같은 이벤트의 전파와 핸들링을 담당하는 매니저 클래스를 만드는 것은 빈말로도 쉽다고 말하기는 어려운 일이었지만, 실제로 컨테이너 프래그먼트를 구현하는 입장에서는 로직이 매우 단순해지는 효과가 있습니다.
@Override
public boolean rewind() {
if (navigateIndexList.size() > 1) {
navigateIndexList.remove(navigateIndexList.size() - 1); // remove current
int position = navigateIndexList.remove(navigateIndexList.size() - 1);
TabLayout.Tab tab = tabs.getTabAt(position);
if (tab != null) {
tab.select();
}
return true;
} else {
Logger.meh("No history");
return false;
}
}
컨테이너 프래그먼트를 구현할 때는 만약 해당 컨테이너가 뒤로가기를 처리할 메인 컨테이너 역할을 담당하는 프래그먼트라면 해당 인터페이스를 선언해주고 rewind 메소드만 구현하면 됩니다. 위 메소드의 경우 여러 개의 탭을 가지고 있는 컨테이너가 뒤로가기 버튼이 눌렸을 때 히스토리가 존재할 경우 이전 탭으로 이동하고 히스토리가 존재하지 않을 경우 상위 컨테이너로 뒤로가기 동작을 넘겨서 탭 컨테이너 자체가 이전 프래그먼트로 돌아가도록 하는 코드 입니다. 이와 같은 형태로 코드를 작성할 수 있다면 디자이너 들이 어떤 괴이한 형태의 네비게이션을 요구하더라도 그럭저럭 잘 대응해줄 수 있습니다.
서비스 호출 단순화 하기
사실 저는 안드로이드 애플리케이션 개발을 준비할 때 화면이 복잡해질 것을 미리 부터 걱정하고 화면처리를 위한 클래스들을 이것저것 만드는데 집중했던 것에 비해서 비즈니스 로직이 매우 복잡해지는 것은 크게 신경쓰지 않았었는데, 저희가 개발하는 솔루션의 경우 매우 복잡한 비즈니스 로직들은 대부분 서버쪽에 존재했기 때문입니다. 서버에서 실질적인 비즈니스 로직을 담당해줄 경우 클라이언트가 수행하는 비즈니스는 일반적으로 입력 값을 검증하고 네트워크를 호출하며 네트워크의 응답을 화면에 반응하는 정도의 로직으로 이루어지는 경우가 많습니다.
때문에 안드로이드의 클라이언트 로직은 대부분 네트워크 호출과 응답을 중심에 두고 그 주변에 UI 객체의 조작을 두는 경우가 많은데, 초반에 설명했던 것 처럼 여기에는 네트워크의 호출과 UI의 처리가 서로 다른 스레드를 가져야 된다는 점이 개발을 어렵게 만드는 요소였습니다. 특히나 파일을 저장할 때와는 다르게 네트워크의 호출은 StrictMode를 설정하지 않더라도 UI 스레드에서 동작할 경우 무조건 앱을 중단시켜버리는 특성이 있기 때문에 스레드의 구분이 강제되었습니다.
이와 같은 어려움이 있기에 안드로이드에서 네트워크 호출을 담당해주는 대부분의 오픈소스들은 화면단에서 호출하더라도 해당 호출을 큐에 담아두고 있다가 별도 스레드에서 순차적으로 보내주고, 결과를 화면단으로 다시 콜백해주는 기능을 가지고 있습니다. 예를 들어서 OkHttp의 경우 다음과 같은 형태로 네트워크 호출을 할 수 있습니다.
Call<RegistrationResponse> registrationCall = ri.list(registrationRequest);
registrationCall.enqueue(new Callback<RegistrationResponse>() {
@Override
public void onResponse(Call<RegistrationResponse> call, Response<RegistrationResponse> response) {
}
@Override
public void onFailure(Call<RegistrationResponse> call, Throwable t) {
}
});
이 코드는 UI 스레드에서 진행되어도 문제를 발생시키지 않습니다. 또한 응답 결과를 바로 호출한 화면에 반영할 수 있기 때문에 매우 깨끗하게 코드를 작성할 수 있습니다. 대부분의 프로젝트에서는 이 정도만으로도 충분히 대부분의 네트워크 호출을 커버할 수 있습니다. 하지만 클라이언트 로직도 더 복잡해질 수 있습니다. 예를 들어서 위 호출의 결과에서 특정 날짜를 받아와서 다시 공통코드 값을 받아오는 로직이 필요하다고 한다면,
registrationCall.enqueue(new Callback<RegistrationInfoListResponse>() {
@Override
public void onResponse(Call<RegistrationInfoListResponse> call, Response<RegistrationInfoListResponse> response) {
Call<DiagnosisCodeList> codeCall = codeInterface.diagnosisCodeList(new CommonCodeRequest(response.body().getCurrentDate()));
codeCall.enqueue(new Callback<DiagnosisCodeList>() {
@Override
public void onResponse(Call<DiagnosisCodeList> call, Response<DiagnosisCodeList> response) {
}
@Override
public void onFailure(Call<DiagnosisCodeList> call, Throwable t) {
}
});
}
@Override
public void onFailure(Call<RegistrationInfoListResponse> call, Throwable t) {
}
});
네트워크의 호출의 콜백에서 다시 네트워크 호출이 이루어지면 콜백이 중첩되게 됩니다. 이러면 에러 처리의 경우 어디에서 어떻게 처리를 해줘야 될지도 난감해지게 됩니다. 만약에 공통코드의 결과를 받아와서 다시 네트워크 호출이 이루어져야 된다면 코드가 더 엉망이 될 수도 있습니다. 그렇기 때문에 이런 문제를 사전에 풀어야 될 필요가 있었습니다. 매우 단순하게 생각하면, 비즈니스 로직이라는 것은 결국 뭔가를 호출하고 받아오고 계산하고 UI에 반영하는 일련의 작업들의 집합입니다. 문제를 조금 더 단순하게 풀어내기 위해서 UI는 비즈니스 로직의 호출과 결과의 반영에만 개입한다고 가정하겠습니다. ‘비즈니스 로직을 수행하는 중간에 UI에 뭔가를 반영하는 일이 절대 없다고 가정할 수 있나?‘라고 생각할 수 있지만 그 경우에는 이벤트 버스를 사용하면 되기 때문에 (그리고 미리 이벤트가 스레드를 넘어 다닐 수 있도록 만들었기 때문에) 문제가 되지 않았습니다. 이러한 일련의 비즈니스 로직을 전부 별도 스레드에서 동작하도록 묶어버리면 개발자들이 큰 신경을 쓰지 않아도 다수의 코어를 활용하도록 유도할 수 있습니다. 안드로이드에는 이미 AsyncTask라는 매우 좋은 비동기 클래스가 존재하므로 해당 클래스를 살짝 래핑하여 더욱 단순한 형태로 바꿔주면 다음과 같은 형태가 될 수 있습니다.
public class RegistrationInfoTask extends ServiceTask<RegistrationInfo, RegistrationList> {
@Override
protected RegistrationInfoList go(RegistrationInfoRequest... params) throws Exception {
// do something in background
}
}
ServiceTask 클래스는 AsyncTask를 상속한 클래스로, 입력값과 출력값을 제네릭으로 정의하도록 되어 있으며 실제 비즈니스 로직이 작성되는 하나의 추상 메소드만 가지고 있습니다. 개발자들은 go 메소드 내부에 비즈니스 로직을 구현하고 그 결과를 반환하기만 하면 됩니다. 이 떄 ServiceTask 클래스는 리턴값이 AsyncTask의 onPostExecute 메소드로 넘어왔을 때, 별도의 콜백 클래스로 결과를 포스팅 해줍니다. 이 때 실제 UI 스레드에서 해당 로직을 호출하는 부분은 다음과 같이 작성됩니다.
RegistrationInfoTask task = new RegistrationInfoTask(new ServiceReceiver<RegistrationInfoList>() {
@Override
public void onProgress(ServiceProgress progress) {
}
@Override
public void onResult(RegistrationList result) {
}
@Override
public void onFail(ServiceError error) {
}
});
task.execute(registrationInfo);
비동기 로직의 수행 결과가 AsyncTask 내부의 onPostExecute 메소드에서 수행되는 것이 아니라 콜백으로 전달되기 때문에 UI 스레드에서 성공한 결과 혹은 실패한 결과와 하나의 타입으로 통일시킨 진행상황을 처리하도록 구성했습니다. 해당 결과를 받아내는 리시버 클래스의 경우 별도 클래스로 만들거나 액티비티 혹은 프래그먼트가 직접 해당 인터페이스를 구현하여 처리하도록 구성할 수도 있지만 일반적인 경우 위와 같이 익명 클래스로 처리됩니다. 이는 대부분의 비즈니스 로직의 결과 처리가 일회성으로 이루어지기 때문입니다. 이와 같은 코드는 개발자가 UI쪽 개발을 진행하다가 네트워크 호출등 비동기 로직을 수행하여야 될 때, 코드의 흐름이 끊기지 않도록 해주는 장점도 있습니다. 실제로 위 네트워크 호출은 task.execute 에서 날아가고 그 수행 결과도 바로 위에 정의됩니다. UI쪽에서 처리할 동작은 UI 클래스에, 비동기 처리해야될 로직은 비동기 클래스에 몰아버려서 조금 더 현재 관심사에 집중할 수 있도록 해줍니다.
반대로 비동기 클래스의 내부에서는 실제 비즈니스 로직의 구현에만 집중하면 되는데, 메소드 전체가 비동기 동작으로 별도의 스레드에서 수행되기 때문에 개발자들은 그냥 자바 프로그래밍을 하면 됩니다. 특히나 OkHttp의 경우 .enqueue 메소드로 호출하면 네트워크 호출을 비동기로 수행해주지만 .execute 메소드로 호출하면 네트워크 호출을 동기로 호출해주는 큰 장점이 있는데, 비동기 스레드 내에서 네트워크 호출이 동기로 이루어질 경우 여전히 안드로이드 OS에 의해서 블로킹 당하지 않으면서도 네트워크 호출이 완료될 떄 까지 기다렸다가 다음 로직을 연속으로 수행할 수 있도록 해줍니다. 예를 들어서 위에서 콜백 지옥에 빠졌던 코드는 다음과 같이 바뀝니다.
String currentDate = registrationCall.execute().body().getCurrentDate();
Call<DiagnosisCodeList> codeCall = codeInterface.diagnosisCodeList(new CommonCodeRequest(currentDate));
DiagnosisCodeList codeList = codeCall.execute().body();
네트워크 호출이 동기화 됨으로써 순차적인 네트워크 호출을 포함하는 클라이언트 로직이 대단히 간단하게 바뀌었습니다. 개발자 입장에서도 순차적으로 로직을 작성하고 최종적으로 UI에 반영할 결과만 반환하면 되기 때문에 생각의 흐름을 조금 더 단순하게 가져갈 수 있는 장점이 있습니다. OkHttp의 경우 안 쓸 이유가 없을 정도로 훌륭한 네트워크 라이브러리였기 때문에 저희도 그 동안의 안드로이드 솔루션 개발에 사용했던 Volley를 버리고 OkHttp 기반의 아키텍처를 준비했습니다. 실제로는 OkHttp를 래핑한 Retrofit을 사용하였는데, Retrofit은 OkHttp를 HTTP 클라이언트로 사용하면서 Rest 기반의 서버 호출을 매우 단순하게 구성할 수 있도록 지원해주는 라이브러리 입니다. Retrofit이 가지고 있는 가장 큰 강점은 호출하고자 하는 서비스의 원형을 인터페이스로 정의해주기만 하면 해당 호출의 구현채를 만들어 준다는 점인데, 예를 들어서 다음과 같은 인터페이스를 정의하면,
public interface RegistrationInterface {
@POST("patient/registration")
Call<RegistrationResponse> list(@Body RegistrationRequest request);
}
특정 주소에 patient/registration의 패스를 가지는 POST방식의 네트워크 호출을 다음과 같이 생성할 수 있습니다.
RegistrationInterface ri = retrofitClient.create(RegistrationInterface.class);
네트워크 호출을 위해서 개발자가 실제로 정의해야 되는 것은 호출 정보 (주소, 메소드)와 요청/응답 등 인터페이스 정의서에 정의되어 있는 내용이 전부이고 기타 잡다한 코드는 작성하지 않아도 되기 때문에 불필요한 곳에 신경을 쓰지 않아도 됩니다. 다만 실제로는 Retrofit의 create 메소드를 이용하여 바로 네트워크 호출을 수행하지는 않고 이를 대행해주는 별도의 클래스를 사용하도록 가이드 했는데, 해당 호출은 다음과 같은 형태를 가집니다.
RegistrationInterface ri = ServiceCenter.generateService(RegistrationInterface.class, RegistrationDemo.class);
사실 일반적인 서비스의 생성은 굳이 별도 클래스로 래핑을 하지 않아도 될 정도로 Retrofit이 군더더기 없이 제공하고 있기 때문에 큰 상관이 없었으나 저는 솔루션이 네트워크 접속 없이도 동작할 수 있도록 만드는 것이 목표였기 때문에 위와 같이 데모 서비스를 같이 전달하도록 클래스를 만들었습니다. 데모 클래스는 역시나 순수한 자바 로직으로만 이루어진, 일종의 가상 서버라고 할 수 있는데 리퀘스트 객체를 받아서 임의의 리스폰스 객체를 반환해주는 역할을 수행합니다.
public class RegistrationDemo extends BaseDemo<RegistrationInterface> {
@Override
public Call<RegistrationResponse> list(@Body RegistrationRequest request) {
RegistrationResponse list = new RegistrationResponse();
// 중략...
return delegate.returningResponse(list).list(request);
}
}
데모 클래스는 결국 사전에 정의한 네트워크 인터페이스의 구현채라고 할 수 있는데, 개발자는 각자 재량껏 반환해야 되는 list 객체 내에 그럴듯한 가짜 데이터를 채워주면 됩니다. 이와 같은 역할을 지원하기 위해서 이미 가짜 데이터 생성을 위한 모듈을 만들어 두었습니다. 이렇게 작성하여 데모 클래스를 전달해줄 경우 ServiceCenter 클래스는 현재 앱이 데모 모드이면 데모 모드의 구현채 목업을, 데모 모드가 아니면 실제 네트워크 호출을 수행하도록 지원해 줍니다. Retrofit은 이런 경우에 사용하라고 목업 기능까지 지원하므로 실제로는 어렵지 않게 데모 모드를 구성할 수 있었습니다.
NetworkBehavior networkBehavior = NetworkBehavior.create();
networkBehavior.setDelay(300, TimeUnit.MILLISECONDS);
networkBehavior.setFailurePercent(10);
networkBehavior.setVariancePercent(30);
MockRetrofit mock = new MockRetrofit.Builder(retrofitClient).networkBehavior(networkBehavior).build();
특히나 Retrofit의 목업 기능의 경우 목업 결과를 반화할 때 임의의 딜레이를 줄 수도 있고, 딜레이에 일종의 편차를 줄 수도 있으며, 일정 확률로 호출이 실패하도록 (에러를 반환하도록) 할 수도 있습니다. 이러한 지원은 데모 모드의 활용을 단순히 서버 접속이 안 될 때 보여주는 용도가 아닌 테스트용으로 확장할 수 있도록 해주는데, 네트워크 호출이 매우 느린 상황을 시뮬레이션 할 수도 있으며, 서버 상태가 좋지 않아서 네트워크 호출이 가끔 실패하는 상황까지 가상으로 만들어낼 수 있기 때문에 사전에 조금 더 단단한 솔루션을 만들 수 있도록 도와줍니다.
네트워크 전송구간 암호화 하기
데이터, 저장소, 이벤트, 화면, 네트워크에 대한 준비가 끝나고 나서야 비로소 보안에 대해서 생각을 해볼 여유를 가지게 되었습니다. 우리 회사의 경우 솔루션을 출시하기 위한 보안 기준이 이미 존재하고 있으며, 특히나 저희 처럼 의료 정보를 다루는 솔루션의 경우 더더욱 데이터의 보안에 대해서 신경을 쓸 수 밖에 없었습니다. 안드로이드 앱의 보안은 디바이스 내에 저장되는 데이터들에 대한 보안과 네트워크로 주고 받는 패킷에 대한 보안으로 나눌 수 있습니다. 디바이스 내에 저장되는 데이터들의 경우 기본적으로 SharedPreference 혹은 InternalStorage를 사용하면 외부에 노출되지 않지만, 디바이스를 루팅할 경우 꺼낼 수 있기 때문에 이 경우에도 암호화를 할 필요성이 있습니다. 물론 디바이스내에 저장되는 데이터 혹은 파일에 대한 암호화는 워낙 일반적인 경우이기 때문에 사용자가 앱에 비밀번호를 설정하면 해당 비밀번호를 이용하여 데이터를 암호화 하고, 추후 앱을 다시 기동했을 때 비밀번호를 입력해야만 데이터에 대한 복호화를 수행할 수 있도록 구성해주는 일반적인 해답이 존재했습니다.
이 경우 비밀번호를 입력하기 이전 시점에 저장되는 데이터에 대한 암호화는 어떻게 할지에 대한 고민과 비밀번호를 또 어떻게 이리저리 늘리고 솔트(Salt)를 추가할지 등등에 대한 고민(실제로는 어떤 오픈소스를 사용할지에 대한 고민) 정도를 고려해주면 큰 어려움 없이 저장소 암호화를 구현할 수 있습니다. 실제로 저희의 경우 비밀번호 입력 시점 이전에는 저장소를 많이 사용하지는 않고, 굳이 필요한 경우 네트워크에서 받아온 키와 디바이스ID, 앱의 설치 시간등을 조합하여 패스워드 없이 암호화 키를 사용하도록 구성하였으며 비밀번호 입력 시점 이후에는 PBKDF2를 Key derivation function으로 사용하였는데, 별 문제는 없었습니다. 다만 저장소 API를 제공할 때 개발자가 사용하는 모든 save / read 메소드에 암호화를 걸어서 개발자는 자기 데이터가 암호화 되는지도 모르고 데이터를 저장하고 읽어올 수 있도록 구성했습니다.
저장소 암호화는 큰 고민 없이 끝낼 수 있었지만, 네트워크로 전송되는 패킷에 대한 암호화는 큰 고민이 있을 수 밖에 없었습니다. 저희 솔루션의 경우 서버가 Rest 방식으로 구성된 것은 아니었지만, 기본적으로 HTTP와 JSON을 이용하여 데이터를 주고받았습니다. 물론 실제로 릴리즈 되는 시점에는 HTTPS를 사용하기는 했지만, 최악의 상황을 가정하면 HTTPS 역시 중간자 공격(MITM Attack)에서 자유로울 수는 없었기 때문에 여전히 요청과 응답이 노출될 가능성과 조작될 가능성을 가지고 있었습니다. 회사에 네트워크 구간을 평문으로 하면 안된다는 보안 기준은 없었지만 해당 구간을 암호화 할 경우 이후 다른 보안 요소들을 처리할 때 매우 유리한 고지를 점령할 수 있었습니다.
 
저희는 저장소에 저장되는 파일을 암호화 할 때 저희는 평문을 암호화하고, 암호문을 평문으로 복호화하는데 AES를 사용하였는데 AES는 Initial Vector와 Secret이 있으면 암호화 및 복호화에 사용되는 키를 생성할 수 있습니다. 즉 네트워크로 전송되는 데이터 역시 특정한 키를 생성하면 암호화하여 보낼 수 있습니다. 문제는 암호화 된 json 을 복호화 하기 위해서는 서버에서도 같은 키를 가지고 있어야 된다는 점입니다. 여기에서 매우 강한 딜레마가 발생하게 되는데, 서로 같은 키를 가지고 있어야 같은 키로 암호화 및 복호화 작업을 수행할 수 있는데 그 키를 전달하는 과정은 평문으로 이루어질 수 밖에 없다는 점입니다. 이 딜레마는 암호화 된 네트워크 전송의 가장 어려운 고리입니다.

저희는 저장소에 저장되는 파일을 암호화 할 때 저희는 평문을 암호화하고, 암호문을 평문으로 복호화하는데 AES를 사용하였는데 AES는 Initial Vector와 Secret이 있으면 암호화 및 복호화에 사용되는 키를 생성할 수 있습니다. 즉 네트워크로 전송되는 데이터 역시 특정한 키를 생성하면 암호화하여 보낼 수 있습니다. 문제는 암호화 된 json 을 복호화 하기 위해서는 서버에서도 같은 키를 가지고 있어야 된다는 점입니다. 여기에서 매우 강한 딜레마가 발생하게 되는데, 서로 같은 키를 가지고 있어야 같은 키로 암호화 및 복호화 작업을 수행할 수 있는데 그 키를 전달하는 과정은 평문으로 이루어질 수 밖에 없다는 점입니다. 이 딜레마는 암호화 된 네트워크 전송의 가장 어려운 고리입니다.
서로 키 교환을 하지 않고 서버와 클라이언트가 각각 소스코드 내에 같은 암호화 키를 가지고 있는 방식도 생각할 수 있습니다. 하지만 안드로이드 앱은 리버스 엔지니어링에 취약하다는 단점이 있으며, 키가 고정되기 떄문에 한 번 노출되면 끝장이라는 위험성이 있기 때문에 별로 좋은 생각은 아니었습니다. 물론 이 단점을 보완하기 위해 JNI를 이용하여 민감한 코드를 C로 작성한다거나 KeyStore를 활용하거나 하는 등의 기법이 있었지만 조금 더 단순한 형태로 문제를 해결해보고자 했습니다.
Diffie-Hellman 키 교환 알고리즘은 E2E(End-To-End) 네트워크에서 전송되는 내용에 대한 암호화를 위해서 많이 사용하는 알고리즘인데, 서로 다른 클라이언트가 각자 공개키(Public Key)와 개인키(Private Key)의 암호쌍을 생성한 뒤 서로간의 공개키 교환 만으로 서로 공유하는 새로운 암호화 키를 생성할 수 있도록 해주는 알고리즘 입니다. 네트워크를 통해서 교환되는 것은 공개키이기 때문에 노출되어도 상관 없는 값이며, 실제로 공유 암호화 키를 생성하기 위해서는 전달되지 않는 개인키가 필요하기 때문에 중간에 공개키를 알아내더라도 암호화에 쓰이는 키를 만들어낼 수 없습니다.
실제로 전송구간 암호화 절차는 다음과 같이 진행됩니다. 우선 클라이언트와 서버가 각각 임의의 공개키 - 개인키 쌍을 만들어냅니다. 코드는 사용하는 시큐리티 프로바이더에 따라서 달라질 수 있습니다.
public static KeyPair generateKeyPair() throws NoSuchProviderException, NoSuchAlgorithmException, InvalidAlgorithmParameterException {
ECGenParameterSpec ecParamSpec = new ECGenParameterSpec("secp224k1");
KeyPairGenerator kpg = KeyPairGenerator.getInstance("ECDH", "SC");
kpg.initialize(ecParamSpec);
KeyPair keyPair = kpg.generateKeyPair();
return keyPair;
}
평범한 네트워크 호출을 이용하여 만들어낸 개인키 / 공개키 쌍 중 공개키를 당당하게 교환합니다.
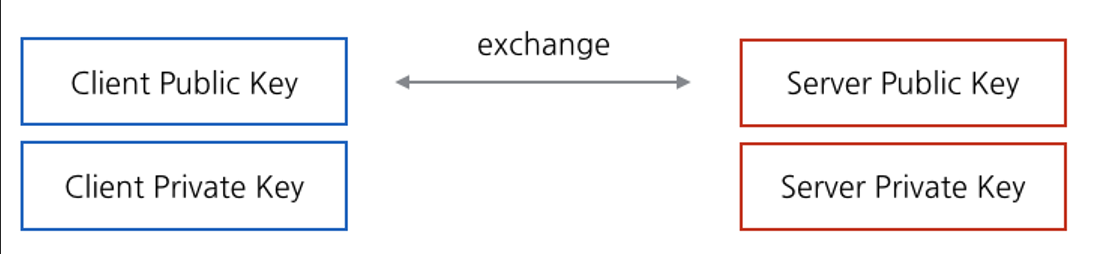
그러면 클라이언트와 서버는 이제 서로의 공개키를 가지고 있게 됩니다.

이제 자신의 개인키와 상대의 공개키에 소수의 성질을 이용한 DH 알고리즘을 적용하여 임의의 암호화 키를 생성해냅니다.
public static byte[] generateSharedSecret(PrivateKey myPrivateKey, PublicKey yourPublicKey) throws NoSuchAlgorithmException, InvalidKeyException {
KeyAgreement ka = KeyAgreement.getInstance("ECDH");
ka.init(myPrivateKey);
ka.doPhase(yourPublicKey, true);
byte[] secret = ka.generateSecret();
return secret;
}
서로 다른 공개키와 개인키를 사용하였지만 알고리즘에 의하여 클라이언트와 서버는 같은 암호화 키를 가지게 됩니다.
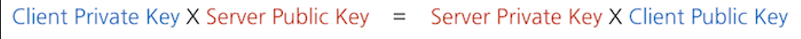
이 과정에서 네트워크를 통해 외부에 노출된 것은 각각의 공개키가 전부이기 때문에 생성된 암호화 키는 결과적으로 외부로부터 안전합니다. 이제 안심하고 해당 키를 이용하여 전송구간 암호화를 진행할 수 있습니다. 물론 서로 생성하는 키는 모두 임의로 생성한 키이며, 필요하면 얼마든지 새로운 임의의 키를 생성한 뒤 교환하여 기존 키를 버리고 새로운 암호화 키를 만들어 낼 수 있기 때문에 암호화 키를 일정 주기로 교체할 수도 있습니다.
물론 모든 네트워크 전송이 일어나기 이전에 키 교환 작업을 진행하여 매번 새로운 키를 사용할 수도 있고 이렇게 하면 보안이 무척 강력해지겠지만, 이 경우 성능 하락이나 네트워크 사용량이 급증하는 단점이 있기 때문에 실제로는 조금 더 넓은 주기를 가지고 암호화 키를 교체하였습니다. 이렇게 될 경우 한 가지 문제가 발생하게 되는데, 기본적으로 E2E 방식의 네트워크에 어울리는 암호화 방식이기 때문에 하나의 서버에 다수의 클라이언트가 접속하는 경우 서버가 다수의 암호화 키를 관리해야 되는 어려움이 생기게 됩니다.
서버는 키 교환 작업을 이용하여 생성한 암호화 키를 어딘가에 저장해두고, 이후 네트워크를 통하여 암호화된 요청이 날아올 경우 헤더에 같이 전송된 디바이스 식별자를 이용하여 저장해둔 암호화 키를 꺼내서 해당 요청을 복호화 합니다. 이 때 암호화 키는 메모리에 저장될 수도 있고 DB에 저장될 수도 있지만 메모리에 저장할 경우 서버가 분산되거나 재부팅 될 경우 키가 다 날아갈 위험이, DB에 저장될 경우 네트워크 요청이 몰리게 될 경우 병목이 발생할 위험이 있습니다. 때문에 단점을 커버할 수 있도록 메모리와 파일을 적절히 활용하는 NoSql DB인 Redis를 사용하였습니다.
Redis는 기본적으로 Key - Value 방식의 데이터를 매우 빠르게 저장하고 읽어올 수 있도록 지원해주면서 동시에 어느정도의 영속성을 보장해주는 저장소이기 때문에 이 경우에는 잘 맞는 선택이 되었습니다. 이러한 기반 기술의 선택이 끝나면 실제로 코드를 작성하여 네트워크 암호화를 진행하였는데, 클라이언트의 경우 네트워크 호출을 위해서 OkHttp를 HTTP 클라이언트로 사용하기 때문에 개발자들이 뭔가 하지 않아도 모든 네트워크 호출에 OkHttp에서 제공하는 Converter 기능을 이용하여 JSON을 암호화 된 문자열로 변환하였습니다.
@Override
public RequestBody convert(TYPE value) throws IOException {
String str = gson.toJson(value);
String encryptedString = SecurityUtil.encrypt(str, SecurityUtil.generateEncryptCipher(Credential.getNetworkKey(), Credential.getNetworkIv()));
return RequestBody.create(MEDIA_TYPE, encryptedString);
}
서로 교환한 키를 가지고 있다는 전제가 있으면 암호화는 정말 쉬워집니다. 역시나 OkHttp에서 제공하는 Interceptor 기능을 이용하여 디바이스의 식별자와 토큰 정보등을 헤더에 같이 넘겨주면 서버는 해당 요청을 복호화 할 수 있습니다. 저희의 경우 평범하게 스프링 서버를 사용하였기 때문에 MessageConveter를 이용하여 요청과 응답을 사전에 핸들링 할 수 있었습니다.
@Override
protected Object readInternal(Class<?> clazz, HttpInputMessage inputMessage) throws IOException, HttpMessageNotReadableException {
String deviceId = inputMessage.getHeaders().get(HeaderValues.DEVICE_ID).get(0);
String encrypted = StreamUtil.copyToString(inputMessage.getBody(), Charset.forName("UTF-8"));
String decrypted = SecurityUtil.decrypt(encrypted, securityDelegate.getDecryptCipher(deviceId));
try {
return gson.fromJson(decrypted, clazz);
} catch (JsonSyntaxException e) {
throw new HttpMessageNotReadableException("Can't read JSON: " + e.getMessage(), e);
}
}
위 코드에서 securityDelegate는 디바이스의 ID를 이용하여 Redis에서 암호화 키를 꺼내서 복호화에 필요한 Cipher를 생성해주는 역할을 수행합니다. 반대로 서버에서 클라리언트로 응답을 보낼 때도 마찬가지로 각자의 Converter에서 암호화 / 복호화 작업을 동일하게 수행해주면 클라이언트와 서버는 최초의 키 교환 요청 단 한 번을 제외하고는 모든 요청과 응답을 암호화 하여 전송할 수 있게 됩니다. 이렇게 각각의 컨버터를 이용해서 암호화를 수행하는 방식의 진짜 좋은 점은 개발자들은 이 구간에 대해서는 전혀 신경을 쓸 필요없이 평소처럼 JSON으로 요청을 보내고 서버에 컨트롤러와 서비스를 만들고 JSON 응답을 처리할 수 있다는 점 입니다. 암호화 및 복호화 과정은 애플리케이션 레이어 보다 한 단계 위 쪽에 있기 때문에 개발에는 아무 영향을 주지 않으면서도 동시에 모든 요청과 응답의 보안성을 강화하는 효과가 있습니다.
물론 DH 방식의 키 교환이 전가의 보도는 아니기 떄문에, 사실 중간자 공격에 취약하다는 단점이 있습니다. 예를 들어서 서버에 도달하기 전에 중간자가 최초 교환되는 공개키를 가로채고 자신의 공개키를 응답으로 보내면 클라이언트는 서버가 아닌 공격자와 암호화 된 연결을 생성한다는 문제가 생기게 되며, 같은 방식으로 공격자가 서버와도 암호화 된 연결을 만들어내서 중간에 패킷을 가로챌 위험이 있습니다. 때문에 전송구간이 암호화 된다고 다른 보안요소를 모두 생략해도 되는 것이 아니라, 실제로는 파라메터의 위변조나 Replay Attack 등을 방어하기 위하여 꽤 복잡한 토큰의 생성과 검증, 파라메터 위변조 방지 및 상호인증 로직 등 챙길 것은 다 챙겨줘야 조금 더 안전하게 네트워크를 연결할 수 있습니다. 물론 이 경우에도 개발자들이 특별히 신경쓸 것은 없습니다.
Appendix
Part 1 - 저장소
- 보안성을 강화하기 위해서는 저장소 암호화가 고려되어야 합니다.
- 실제 저장소는 Shared Preference, 내부 저장소, 외부 저장소의 구분이 용도에 따라 이루어져야 합니다.
- Shared Preference의 저장은 비동기 Commit을 지원하기 때문에 별도로 스레드 분리를 하지 않아도 됩니다.
- 요구사항이 있다는 전제하에, 조금 더 좋은 개발환경을 위해서는 Bitmap 데이터의 저장 메소드를 지원하는 것이 좋습니다.
- 조금 더 다양한 케이스에 대응하기 위하여 저장소의 입출력을 비동기와 동기 사이에서 전환할 수 있도록 지원해주는 API를 작성할 수 있습니다.
Part 2 - 데이터
- 등장 확률을 가지는 데이터를 처리하기 위해서는 입력값을 정규화 해야 합니다.
- 원본 데이터의 로딩은 정적으로 이루어질 수도 있으나 데이터가 많아 질 경우 애플리케이션의 기동시간을 느리게 만들 위험이 있습니다. 데이터를 별도 파일에 저장해두고 동적으로 불러오는 경우 일정 기간동안 데이터가 준비되지 않을 수 있습니다.
- 실제로 정규분포를 이용하여 나이를 생성하면, 낮은 확률로 정규분포에 바깥에 있는 데이터들이 나이를 마이너스로 만들 수 있으니 해당 부분의 처리가 추가되어야 합니다.
- 랜덤하게 생성되는 데이터가 정말로 확률에 맞추어서 제대로 분포된 데이터를 가지고 있는지에 대한 단위 테스트는 다수의 시행을 통해 확률을 계산하는 것으로 이루어져야 되기 때문에 해당 조건까지 포함한 테스트 케이스의 작성은 생각보다 어렵습니다.
Part 3 - 이벤트 버스
- 저희가 이벤트 버스 용도로 사용한 오픈소스인 Otto는 프로젝트가 시작되자 귀신같이 Deprecate 되었습니다. 여전히 잘 동작하기는 하지만 Deprecate 된 오픈소스의 사용에 거부감이 있으신 분은 RxJava / RxAndroid를 이용한 이벤트 버스의 구성이 현재 트랜드이므로 참고 부탁드리겠습니다.
- 이벤트의 발행은 어떤 코드에서도 가능하지만, 구독은 이벤트 버스에 등록된 클래스들만 가능합니다. 이벤트 버스에 지나치게 많은 객체가 등록되는 것을 막기 위해서 가급적이면 이벤트를 구독하는 클래스는 라이프사이클을 컨트롤 할 수 있는 액티비티와 프래그먼트로 한정하는 것이 좋습니다.
- 이벤트 구독 메소드는 상속이 되지 않습니다. 즉 B 액티비티가 A 액티비티를 상속받고, 실제로 화면에 B 액티비티가 떠 있는 경우 A 액티비티에 작성한 @Subscribe 메소드는 호출되지 않습니다. 이 문제를 해결하기 위해서는 구독 메소드를 별도의 내부 클래스에 포함시키고 해당 클래스를 별도로 이벤트 버스에 등록하여야 합니다.
- 토스트, 스낵바, 다이얼로그의 표시 등 전역적으로 표시되는 UI 피드백을 이벤트 버스를 통해 표시할 수 있도록 사전에 준비해주면 비즈니스 로직 중간의 피드백 표시가 쉬워지는 효과를 가져올 수 있습니다.
- 키보드의 나타남과 사라짐에 대한 감지는 매니페스트 파일에 화면 모드가 adjustResize로 지정되어 있는 경우에만 가능합니다.
Part 4 - 프래그먼트
- 공통 프래그먼트 클래스를 생성하여 레이아웃을 자동으로 Inflate 시키고 이벤트 버스에 대한 등록 및 해제, 저장소의 제공 등을 진행시켜줄 수 있습니다.
- 중첩 프래그먼트가 빠르게 replace 되는 경우 발생하는 예외를 막기 위해서 onDetach 라이프사이클에 다음과 같이 리플렉션을 이용한 임의 처리를 추가해주는 것은 도움이 됩니다.
Field childFragmentManager = Fragment.class.getDeclaredField("mChildFragmentManager");
childFragmentManager.setAccessible(true);
childFragmentManager.set(this, null);
- 모든 프래그먼트를 리테인(Retain) 하고자 하는 경우 중첩 프래그먼트의 컨테이너 프래그먼트 내에 배치되는 자식 프래그먼트들은 컨테이너 프래그먼트의 리테인 설정을 상속받기 때문에 컨테이너는 리테인을 유지시키고, 리테인을 해제시켜야 예외가 발생되지 않습니다. 컨테이너가 중첩될 경우에도 마찬가지로 최상위 컨테이너만 리테인을 유지시켜야 합니다.
- 버터나이프(ButterKnife) 등의 뷰 인젝션 라이브러리를 사용하는 것은 코드를 단순하게 만들어주면서 동시에 어느정도의 생산성 향상 효과를 가져올 수 있습니다.
Part 5 - 비즈니스 로직
- 상대적으로 좋은 UX를 유지하기 위해서는 모든 태스크를 직렬화 하여 별도 저장소에 저장할 수 있도록 구상하는 것도 좋은 방식인데, 태스크를 직렬화 할 경우 실패한 태스크나 실행 중 앱이 재실행 되는 경우에도 해당 태스크를 재실행 할 수 있습니다. (저희는 안 했습니다.)
- 모든 네트워크 호출과 태스크 진행은 상황에 따라 취소될 수 있도록 구성해주어야 결과 처리 콜백에서 모든 UI 객체에 null 체크를 추가하는 공수를 덜어줄 수 있습니다. OkHttp의 경우 Call 객체에 cancel 메소드가 포함되어 있으며, AsyncTask의 경우 스레드에 인터셉트를 걸어주는 기능이 포함되어 있습니다.
- 설계에 따라서 비동기 태스크들을 다시 동기화하여 순차적으로 처리하거나 결과에 대한 콜백을 하나로 묶어야 될 필요가 있을 수도 있습니다.
- 이벤트 버스를 사전에 구성해둔 경우 서비스의 진행상황을 중간에 퍼블리싱하는 onProgressUpdate 메소드를 정말로 서비스의 진행상황을 통보해주는 용도로 사용할 수 있습니다. 그리고 실제로 요청 - 응답 방식의 비즈니스가 대부분인 솔루션인 경우 대부분 진행상황의 통보는 필요하지 않은 기능이 되므로 일반적인 케이스에서는 생략이 가능합니다.
Part 6 - 보안
- DH 방식의 공유키 생성은 자바의 기본 시큐리티 프로바이더에서 제공하지 않는 기능일 수 있으며 별도 오픈소스 프로바이더를 사용해야 될 수 있습니다.
- 로그인, 인증, 토큰, 토큰의 암호화 및 Replay Attack에 대한 방지등에 대한 이야기는 제외되었습니다. 프로젝트 보안상의 이유는 아니고 쓰다가 지쳤습니다.
- 저희의 경우 평문 전송과 암호화 된 전송을 미디어 타입이 application/json인지 text/plain인지 구분하는 형태로 개발하였습니다.
- 암호화 된 전송 채널만을 남겨둔 경우 별도의 REST 클라이언트를 이용하여 서비스 호출을 테스트 해보거나 종료 직전 성능 테스트를 받을 때 문제가 될 수 있기 때문에 개발서버에서는 평문 전송 채널을 남겨둘 필요가 있습니다.
References
- Improve Code Inspection with Annotations
- The Shortcomings of Android Thread Annotations
- Android Support Annotations 라이브러리를 활용한 결함 탐지
- Keeping Your App Responsive
- 안드로이드 멀티스레딩
- greenrobot/EventBus
- square/Otto
- Implementing an Event Bus With RxJava - RxBus
- Android’s matryoshka problem
- 안드로이드 앱 성능 최적화
- Square/Retrofit
- Square/OkHTtp
- 안드로이드 비동기 프로그래밍
- Diffie–Hellman key exchange
- 안전한 패스워드 저장
- 더 안전한 대화를 위한 Letter Sealing
- 안드로이드 시큐리티 인터널
- 안드로이드 해킹과 보안
- 안드로이드 보안과 침투 테스팅